An Overview of Context Capturing Techniques in NLP
Article Sidebar
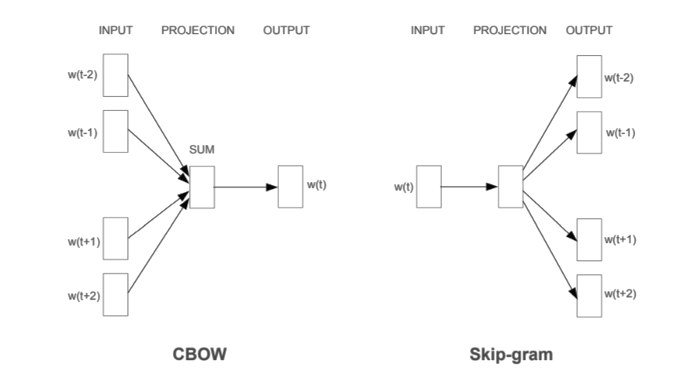
Main Article Content
Abstract
In the NLP context identification has become a prominent way to overcome syntactic and semantic ambiguities. Ambiguities are unsolved problems but can be reduced to a certain level. This ambiguity reduction helps to improve the quality of several NLP processes, such as text translation, text simplification, text retrieval, word sense disambiguation, etc. Context identification, also known as contextualization, takes place in the preprocessing phase of NLP processes. The essence of this identification is to uniquely represent a word or a phrase to improve the decision-making during the transfer phase of the NLP processes. The improved decision-making helps to improve the quality of the output. This paper tries to provide an overview of different context-capturing mechanisms used in NLP.
Article Details
References
Modh, Jatin C. “A STUDY OF MACHINE TRANSLATION APPROACHES FOR GUJARATI LANGUAGE.” International Journal of Advanced Research in Computer Science 9, no. 1 (February 20, 2018): 285–88. https://doi.org/10.26483/ijarcs.v9i1.5266.
Siddharthan, Advaith (28 March 2006). "Syntactic Simplification and Text Cohesion". Research on Language and Computation. 4 (1): 77–109. doi:10.1007/s11168-006-9011-1. S2CID 14619244
Manning, Christopher D. “Part-of-Speech Tagging from 97% to 100%: Is It Time for Some Linguistics?” In Computational Linguistics and Intelligent Text Processing, edited by Alexander F. Gelbukh, 6608:171–89. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011. https://doi.org/10.1007/978-3-642-19400-9_14.
Sebastiani, Fabrizio. “Machine Learning in Automated Text Categorization.” ACM Computing Surveys 34, no. 1 (March 2002): 1–47. https://doi.org/10.1145/505282.505283.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global vectors for word representation. In Proceedings of EMNLP, pages 1532–1543. https://nlp.stanford.edu/projects/glove/
Al-Thanyyan, Suha S., and Aqil M. Azmi. “Automated Text Simplification.” ACM Computing Surveys 1 Apr. 2021. ACM Computing Surveys. Web..
Dhawal Khem, Shailesh Panchal, Chetan Bhatt, “Text Simplification Improves Text Translation from Gujarati Regional Language to English: An Experimental Study”, Int J Intell Syst Appl Eng, vol. 11, no. 2s, pp. 316–327, Jan. 2023. VBNCVX
Sebastiani, Fabrizio. “Machine Learning in Automated Text Categorization.” ACM Computing Surveys 34, no. 1 (March 2002): 1–47. https://doi.org/10.1145/505282.505283.
Tellex, Stefanie, Boris Katz, Jimmy Lin, Aaron Fernandes, and Gregory Marton. “Quantitative Evaluation of Passage Retrieval Algorithms for Question Answering,” n.d.
Turian, Joseph, Lev Ratinov, Y. Bengio, and Dan Roth. “A Preliminary Evaluation of Word Representations for Named-Entity,” January 1, 2009.
Socher, Richard, John Bauer, Christopher D. Manning, and Andrew Y. Ng. “Parsing with Compositional Vector Grammars.” In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 455–65. Sofia, Bulgaria: Association for Computational Linguistics, 2013. https://aclanthology.org/P13-1045.
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. Transactions of the Association of Computational Linguistics, 5(1):135–146. https://github.com/facebookresearch/fastText
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. CoRR abs/1301.3781. https://code.google.com/archive/p/word2vec/
Pagliardini, Matteo, Prakhar Gupta, and Martin Jaggi. “Unsupervised Learning of Sentence Embeddings Using Compositional N-Gram Features.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 528–40. New Orleans, Louisiana: Association for Computational Linguistics, 2018. https://doi.org/10.18653/v1/N18-1049.
Cer, Daniel, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St John, Noah Constant, et al. “Universal Sentence Encoder.” arXiv, April 12, 2018. https://doi.org/10.48550/arXiv.1803.11175.
Le, Quoc V., and Tomas Mikolov. “Distributed Representations of Sentences and Documents.” arXiv, May 22, 2014. https://doi.org/10.48550/arXiv.1405.4053.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. https://arxiv.org/abs/1810.04805
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of NAACL, New Orleans, LA, USA, pages 2227–2237. https://allennlp.org/elmo
Oren Melamud, Jacob Goldberger, and Ido Dagan. 2016. Context2vec: Learning generic context embedding with bidirectional LSTM. In Proceedings of CoNLL, Berlin, Germany, pages 51–61.
Lample, Guillaume, and Alexis Conneau. “Cross-Lingual Language Model Pretraining.” arXiv, January 22, 2019. https://doi.org/10.48550/arXiv.1901.07291.
Yang, Zhilin, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. “XLNet: Generalized Autoregressive Pretraining for Language Understanding.” arXiv, January 2, 2020. https://doi.org/10.48550/arXiv.1906.08237.
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-Shot Relation Extraction via Reading Comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 333–342. Association for Computational Linguistics.
Merlo, Paola, and Maria Andueza Rodriguez. “Cross-Lingual Word Embeddings and the Structure of the Human Bilingual Lexicon.” In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), 110–20. Hong Kong, China: Association for Computational Linguistics, 2019. https://doi.org/10.18653/v1/K19-1011.
Artetxe, Mikel, Gorka Labaka, Eneko Agirre, and Kyunghyun Cho. “Unsupervised Neural Machine Translation.” arXiv, February 26, 2018. https://doi.org/10.48550/arXiv.1710.11041.
Conneau, Alexis, Guillaume Lample, Ruty Rinott, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. “XNLI: Evaluating Cross-Lingual Sentence Representations.” arXiv, September 13, 2018. https://doi.org/10.48550/arXiv.1809.05053.
Artetxe, Mikel. “VecMap (Cross-Lingual Word Embedding Mappings).” Python, March 15, 2023. https://github.com/artetxem/vecmap.
Lample, Guillaume, and Alexis Conneau. “Cross-Lingual Language Model Pretraining.” arXiv, January 22, 2019. https://doi.org/10.48550/arXiv.1901.07291.
Mulcaire, Phoebe, Jungo Kasai, and Noah A. Smith. “Low-Resource Parsing with Crosslingual Contextualized Representations.” arXiv, September 18, 2019. https://doi.org/10.48550/arXiv.1909.08744.
Gururangan, Suchin, Ana Marasovi?, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. “Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks.” arXiv, May 5, 2020. https://doi.org/10.48550/arXiv.2004.10964.
Mohammad Taher Pilehvar and Jose Camacho-Collados. 2018. Wic: 10,000 example pairs for evaluating context-sensitive representations. arXiv preprint arXiv:1808.09121. https://arxiv.org/abs/1808.09121
Kulshrestha, Ria. “NLP 101: Word2Vec — Skip-Gram and CBOW.” Medium, October 26, 2020. https://towardsdatascience.com/nlp-101-word2vec-skip-gram-and-cbow-93512ee24314.