Integration of MFCC Extraction and LSTM Algorithm on PYNQ-Z2 for Enhanced Audio Analysis
Article Sidebar
Main Article Content
Abstract
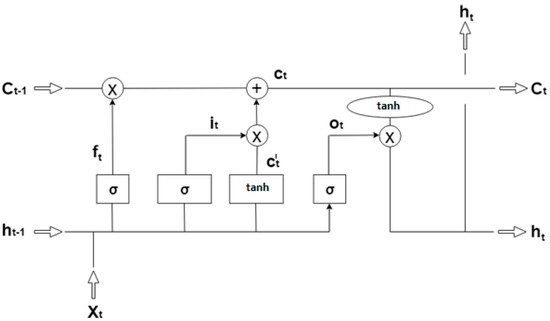
The need for Speech Emotion Recognition (SER) is growing since researchers have found it difficult to interpret human emotions from speech data. SER is very interesting yet very challenging task of human-computer interaction (HCI). The SER application can be benefitted depending on the type of feature extraction technique and model used for classification. Deep Learning has made a great impact in the field of audio, image, video, EEG and ECG classification. The speech signal characteristics and classification model affect how well the SER application performs. The paper briefs about deploying Deep Learning Algorithm on FPGA based board i.e., PYNQ-Z2. MFCC feature extraction technique and LSTM model used for classification of human emotion is implemented on the board. Emotion can be predicted using led buttons on the board.