Improving the Performance of Heterogeneous Hadoop Clusters Using Map Reduce
Article Sidebar
Main Article Content
Abstract
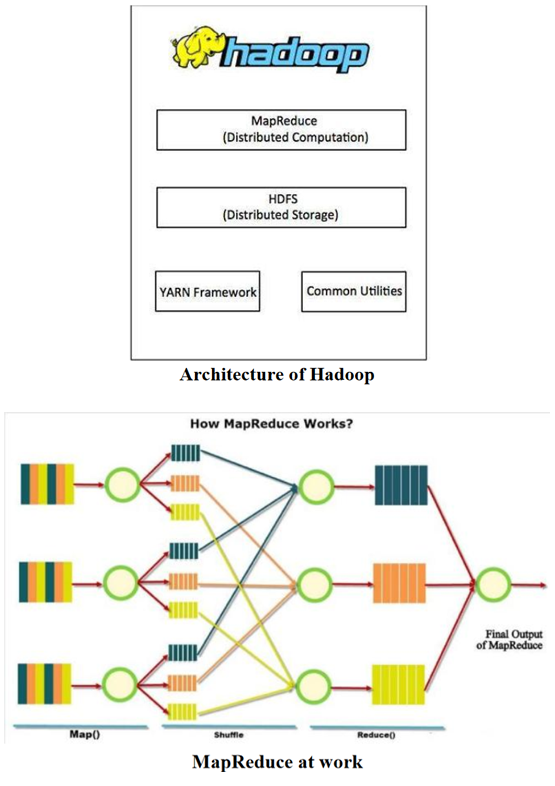
The key issue that emerges because of the tremendous development of connectivity among devices and frameworks is making such a great amount of data at an exponential rate that an achievable answer for preparing it is getting to be troublesome step by step. Thusly, building up a stage for such propelled dimension of data handling, equipment just as programming improvements should be led to come in level with such generous data. To enhance the proficiency of Hadoop bunches in putting away and dissecting big data, we have proposed an algorithmic methodology that will provide food the necessities of heterogeneous data put away .over Hadoop groups and enhance the execution just as effectiveness. The proposed paper intends to discover the adequacy of new calculation, correlation, proposals, and an aggressive way to deal with discover the best answer for enhancing the big data situation. The Map Reduce method from Hadoop will help in keeping up a nearby watch over the unstructured or heterogeneous Hadoop bunches with bits of knowledge on results obviously from the algorithm.in this paper we proposed new Generating another calculation to tackle these issues for the business just as non-business uses can help the advancement of network. The proposed calculation can help enhance the situation of data ordering calculation MapReduce in heterogeneous Hadoop groups. The exposition work and analyses directed under this work have copied very amazing outcomes, some of them being the selection of schedulers to plan employments, arrangement of data in similitude lattice, bunching before planning inquiries and in addition, iterative, mapping and diminishing and restricting the inner conditions together to stay away from question slowing down and execution times. The test led additionally sets up the way that if a procedure is characterized to deal with the diverse use case situations, one could generally lessen the expense of processing and can profit on depending on disseminated frameworks for quick executions.