Ensemble Learning for fraud detection in Online Payment System Fraud Detection in Online Payment System
Article Sidebar
Main Article Content
Abstract
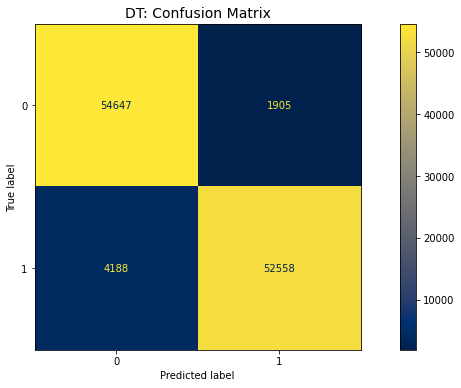
The imbalanced problem in fraud detection systems refers to the unequal distribution of fraud cases and non-fraud cases in the information that is used to train machine learning models. This can make it difficult to accurately detect fraudulent activity. As a general rule, instances of fraud occur much less frequently than instances of other types of occurrences, which results in a dataset which is very unbalanced. This imbalance can present challenges for machine learning algorithms, as they may become biased towards the majority class (that is, non-fraud cases) and fail to accurately detect fraud. In situations like these, machine learning models may have a high accuracy overall, but a low recall for the minority class (i.e., fraud cases), which means that many instances of fraud will be misclassified as instances of something else and will not be found. In this study, Synthetic Minority Sampling Technique (SMOTE) is used for balancing the data set and the following machine learning algorithms such as decision trees, Enhanced logistic regression, Naive Bayes are used to classify the dataset.Majority Voting mechanism is used to ensemble the DT,NB, ELR methods and analyze the performance of the model. The performance of the Ensemble of various Machine Learning algorithms was superior to that of the other algorithms in terms of accuracy (98.62%), F1 score (95.21%), precision (98.02%), and recall (96.75%).