An Enhanced Query Optimization Implemented in Hadoop using Bio-Inspired Algorithm with HDFS Technique
Article Sidebar
Main Article Content
Abstract
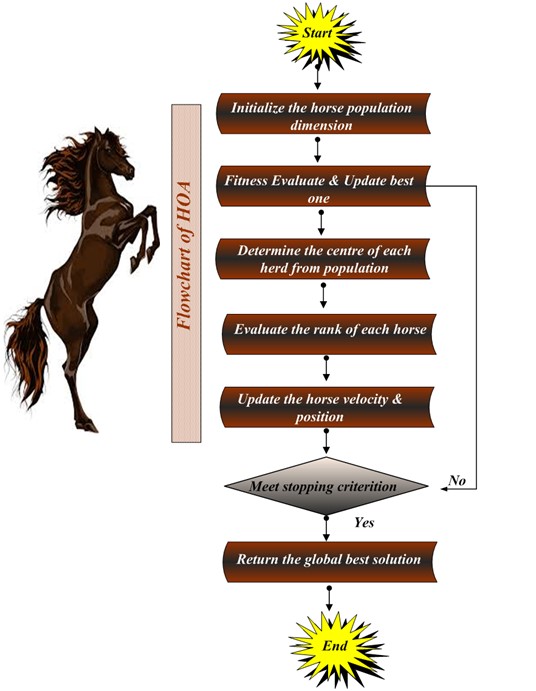
A more effective method for massive data query optimization using HDFS and the Bio-inspired algorithm. Big Data configuration and query optimization are the two phases of the process. To remove redundant data, the input data is first per-processed using HDFS. Then, utilizing entropy calculation, features like closed frequent pattern, support, and confidence are extracted and managed. The Bio-inspired Horse Herd approach is used to group pertinent information based on this outcome. In the second step, the Big Data queries are used to obtain the same features. The optimized query is then located using the Bio-inspired technique, and the similarity assessment procedure is run. The proposed algorithm, according to this research, outperforms other ones that is unique in use. It is challenging to determine the veracity of this claim without more information regarding the experimental setup and the precise measures employed to assess the algorithm's effectiveness. Furthermore, it is unknown how the proposed algorithm stacks up against other cutting-edge query optimization methods. Finally, the assess has efficiency of using this method, more optimistic query achieved and comparison analysis are proved.
Article Details
References
. Rawat, J.S., Kishor, S., Kumari, M.: A survey on query optimization in cloud computing. Int J AdvTechnolEngSci 4(10), 2348 (2016)
. Gu, R., Yang, X., Yan, J., Sun, Y., Wang, B., Yuan, C., Huang, Y.: SHadoop: improving mapreduce performance by optimizing job execution mechanism in hadoop clusters. J Parallel DistribComput. 74(3), 2166–2179 (2014)
. J Wolf, D Rajan, K Hildrum, R Khandekar, V Kumar, S Parekh, and KL Wu 2010, “Flex: A slot allocation scheduling optimizer for mapreduce workloads”, In Proceedings of the ACM/IFIP/USENIX 11th International Conference on Middleware, SpringerVerlag, pp. 1-20
. Barba-González, C., García-Nieto, J., Nebro, A.J., Cordero, J.A., Durillo, J.J., Navas-Delgado, I., Aldana-Montes, J.F.: jMetalSP: a framework for dynamic multi-objective big data optimization. Applied Soft Computing 69, 737–748 (2018)
. Song, J., Ma, Z., Thomas, R., Ge, Yu.: Energy efficiency optimization in big data processing platform by improving resources utilization. Sustainable Computing: Informatics and Systems 21, 80–89 (2019)
. Mahajan, D., Blakeney, C., Zong, Z.: Improving the energy efciency of relational and NoSQL databases via query optimizations. Sustainable Computing: Informatics and Systems 22, 120–133 (2019)
. Rini John, and Nikita Palaskar, “A survey of various query optimization techniques”, International Journal of Computer Applications, vol. 975, pp. 8887
. Roy, C., Pandey, M., Rautaray, S.S.: A proposal for optimization of data node by horizontal scaling of name node using big data tools. In: Proceedings of the 3rd International Conference for Convergence in Technology (I2CT), IEEE, pp. 1–6 (2018)
. Dwivedi, J., Tiwary, A.: Big data analytics: an overview. Int. J. Sci. Technol. Res. 5(07) (2016)
. ElhamAzhir ,MehdiHosseinzadeh , Faheem Khan , and Amir Mosavi : Performance Evaluation of Query Plan Recommendation with Apache Hadoop and Apache Spark. 10(19), 3517(2022)
. Deepak Kumar, Vijay Kumar Jha: An improved query optimization process in big data using ACO-GA algorithm and HDFS map reduce technique. Springer Science+Business Media, LLC, part of Springer Nature (2020)
. Song, J., Ma, Z., Thomas, R., Ge, Yu.: Energy efciency optimization in big data processing platform by improving resources utilization. Sustainable Computing: Informatics and Systems 21, 80–89 (2019)
. Panahi, V.; Navimipour, N.J. Join query optimization in the distributed database system using an artificial bee colony algorithm and genetic operators. Concurr. Comput. Pract. Exp. 2019, 31, e5218.
. Pasquale Salza, FilomenaFerrucci. Speed up genetic algorithms in the cloud using software containers. (2019)
. Mahajan, D., Blakeney, C., Zong, Z.: Improving the energy efciency of relational and NoSQL databases via query optimizations. Sustainable Computing: Informatics and Systems 22, 120–133 (2019)
. Bao, C., Cao, M.: Query optimization of massive social network data based on hbase. In: Proceedings of the IEEE 4th International Conference on Big Data Analytics (ICBDA), pp. 94–97 (2019)
. Sahal, R., Nihad, M., Khafagy, M.H., Omara, F.A.: iHOME: index-based join query optimization for limited big data storage. J. Grid Comput. 16(2), 345–380 (2018)
. Rawat, J.S., Kishor, S., Kumari, M.: A survey on query optimization in cloud computing. Int J AdvTechnolEngSci 4(10), 2348 (2016)
. KiranjitPattnaik, Bhabani Shankar Prasad Mishra: A Review on Parallel Genetic Algorithm Models for Map Reduce in Big Data. International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 IJERTV5IS080400 Vol. 5 Issue 08, August-2016.
. Panahi, V.; Navimipour, N.J. Join query optimization in the distributed database system using an artificial bee colony algorithm and genetic operators. Concurr. Comput. Pract. Exp. 2019, 31, e5218.
. Rani, S.; Rama, B. MapReduce with Hadoop for Simplified Analysis of Big Data, International Journal of Advanced Research in Computer Science, May-June 2017, Volume 8, No. 5, ISSN No. 0976-5697, pp. 853-856.
. Joseph, C.W.; Pushpalatha, B., A Survey on Big Data and Hadoop, International Journal of Innovative Research in Computer and Communication Engineering, ISSN(Online): 2320-9801, March 2017, Vol. 5, Issue 3, pp. 5525-5530.
. Ferrucci, F., Salza, P., and Sarro, F. (2016). Using Hadoop MapReduce for Parallel Genetic Algorithms: A Comparison of the Global, Grid and Island Models - Appendix. https: //doi.org/10.6084/m9.figshare.5091898.
. Fu, W., Menzies, T., and Shen, X. (2016). Tuning for Software Analytics: Is It Really Necessary? Information and Software Technology, 76:135–146.
. Salza, P., Ferrucci, F., and Sarro, F. (2016a). Develop, Deploy and Execute Parallel Genetic Algorithms in the Cloud. In Genetic and Evolutionary Computation Conference (GECCO), pages 121–122.