Data Mining Technique for Breast Cancer Prediction using Fuzzy Theory
Article Sidebar
Main Article Content
Abstract
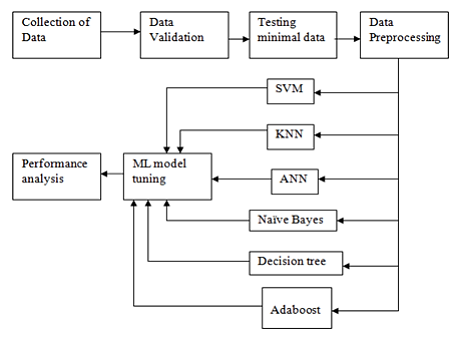
In order to find a reliable approach of breast cancer prediction, Data mining methods are used in the studies provided in this article. This study compares multiple patient clinical data in order to find a reliable model that can predict the occurrence of breast cancer. In this article, the support vector machine (SVM), artificial neural network (ANN), naive bayes classifier, and AdaBoost tree are used as four data mining methods. Furthermore, since it has such a significant impact on the efficacy and efficiency of the learning process, feature space is extensively examined in this work. Combining PCA with other data mining algorithms that use a PCA-like technique to compress the feature space is recommended. This hybrid is intended to assess the effect of feature space reduction. Wisconsin Breast Cancer Database (1991) and Wisconsin Diagnostic Breast Cancer (1995) are two frequently used test data sets that are used to assess the effectiveness of these algorithms. To calculate each model's test error, the method of 10-fold cross-validation is used. The findings of this research show a thorough trade-off between these tactics and also provide a thorough assessment of the models. In practical applications, it is anticipated that feature identification results would help to avoid breast cancer for both doctors and patients.