Survey of Automatic Dysarthric Speech Recognition
Article Sidebar
Main Article Content
Abstract
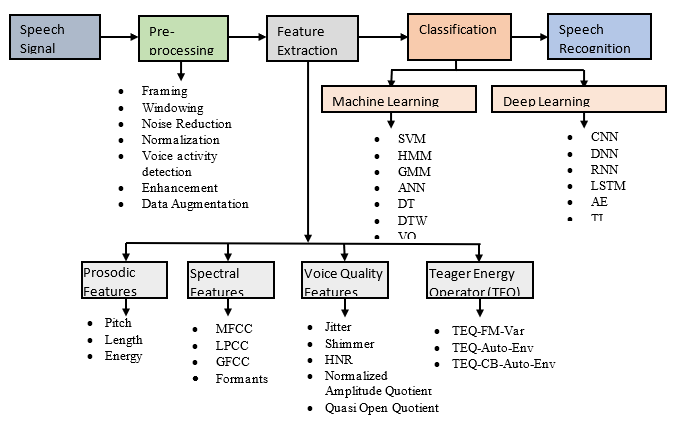
The need for automated speech recognition has expanded as a result of significant industrial expansion for a variety of automation and human-machine interface applications. The speech impairment brought on by communication disorders, neurogenic speech disorders, or psychological speech disorders limits the performance of different artificial intelligence-based systems. The dysarthric condition is a neurogenic speech disease that restricts the capacity of the human voice to articulate. This article presents a comprehensive survey of the recent advances in the automatic Dysarthric Speech Recognition (DSR) using machine learning and deep learning paradigms. It focuses on the methodology, database, evaluation metrics and major findings from the study of previous approaches. From the literature survey it provides the gaps between exiting work and previous work on DSR and provides the future direction for improvement of DSR.