Comprehensive Study of Automatic Speech Emotion Recognition Systems
Article Sidebar
Main Article Content
Abstract
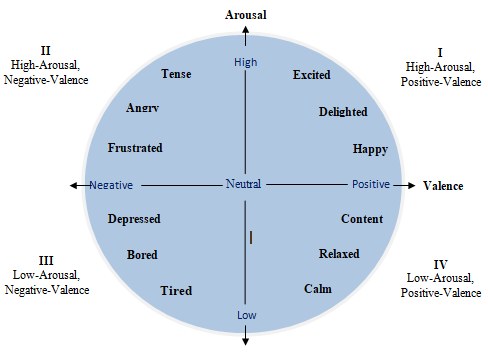
Speech emotion recognition (SER) is the technology that recognizes psychological characteristics and feelings from the speech signals through techniques and methodologies. SER is challenging because of more considerable variations in different languages arousal and valence levels. Various technical developments in artificial intelligence and signal processing methods have encouraged and made it possible to interpret emotions.SER plays a vital role in remote communication. This paper offers a recent survey of SER using machine learning (ML) and deep learning (DL)-based techniques. It focuses on the various feature representation and classification techniques used for SER. Further, it describes details about databases and evaluation metrics used for speech emotion recognition.
Article Details
References
B. W. Schuller, "Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends," Communications of the A.C.M., vol. 61, no. 5, pp. 90–99, 2018.
Bhangale, KishorBarasu, and K. Mohanaprasad. "A review on speech processing using machine learning paradigm." International Journal of Speech Technology 24, no. 2 (2021): 367-388.
Bhangale, KishorBarasu, and MohanaprasadKothandaraman. "Survey of Deep Learning Paradigms for Speech Processing." Wireless Personal Communications (2022): 1-37.
La Mura, Monica, and PatriziaLamberti. "Human-Machine Interaction Personalization: a Review on Gender and Emotion Recognition Through Speech Analysis." In 2020 IEEE International Workshop on Metrology for Industry 4.0 &IoT, pp. 319-323. IEEE, 2020.
Bhangale, Kishor, and MohanaprasadKothandaraman. "Speech Emotion Recognition Based on Multiple Acoustic Features and Deep Convolutional Neural Network." Electronics 12, no. 4 (2023): 839.
Petrushin, Valery A. "Detecting emotion in voice signals in a call center." U.S. Patent 7,940,914, issued May 10, 2011.
Ousmane, AbdoulMatine, TahirouDjara, and Antoine Vianou. "Automatic recognition system of emotions expressed through the face using machine learning: Application to police interrogation simulation." In 2019 3rd International Conference on Bio-engineering for Smart Technologies (BioSMART), pp. 1-4. IEEE, 2019.
Chen, Luefeng, Wanjuan Su, Yu Feng, Min Wu, Jinhua She, and Kaoru Hirota. "Two-layer fuzzy multiple random forest for SERin human-robot interaction." Information Sciences 509 (2020): 150-163.
Yu, Liang-Chih, Lung-Hao Lee, ShuaiHao, Jin Wang, Yunchao He, Jun Hu, K. Robert Lai, and Xuejie Zhang. "Building Chinese affective resources in valence-arousal dimensions." In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 540-545. 2016.
Nicolaou, Mihalis A., HaticeGunes, and Maja Pantic. "Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space." IEEE Transactions on Affective Computing 2, no. 2 (2011): 92-105.
Li, Yongwei, Junfeng Li, and Masato Akagi. "Contributions of the glottal source and vocal tract cues to emotional vowel perception in the valence-arousal space." The Journal of the Acoustical Society of America 144, no. 2 (2018): 908-916.
Parthasarathy, Srinivas, and Carlos Busso. "Ladder networks for emotion recognition: Using unsupervised auxiliary tasks to improve predictions of emotional attributes." arXiv preprint arXiv:1804.10816 (2018).
Larradet, Fanny, RadoslawNiewiadomski, Giacinto Barresi, Darwin G. Caldwell, and Leonardo S. Mattos. "Toward emotion recognition from physiological signals in the wild: approaching the methodological issues in real-life data collection." Frontiers in psychology 11 (2020): 1111.
Akçay, Mehmet Berkehan, and Kaya O?uz. "Speech emotion recognition: Emotional models, databases, features, pre-processing methods, supporting modalities, and classifiers." Speech Communication 116 (2020): 56-76.
Swain, Monorama, AurobindaRoutray, and PrithvirajKabisatpathy. "Databases, features and classifiers for speech emotion recognition: a review." International Journal of Speech Technology 21, no. 1 (2018): 93-120.
Papakostas, Michalis, EvaggelosSpyrou, Theodoros Giannakopoulos, GiorgosSiantikos, DimitriosSgouropoulos, PhivosMylonas, and FilliaMakedon. "Deep visual attributes vs. hand-crafted audio features on multidomain speech emotion recognition." Computation 5, no. 2 (2017): 26.
Özseven, Turgut. "A novel feature selection method for speech emotion recognition." Applied Acoustics 146 (2019): 320-326.
Gao, Yuanbo, Baobin Li, Ning Wang, and Tingshao Zhu. "SERusing local and global features." In International Conference on Brain Informatics, pp. 3-13. Springer, Cham, 2017.
L. Abdel-Hamid, N. H. Shaker and I. Emara, "Analysis of Linguistic and Prosodic Features of Bilingual Arabic–English Speakers for Speech Emotion Recognition," in IEEE Access, vol. 8, pp. 72957-72970, 2020, doi: 10.1109/ACCESS.2020.2987864.
Alex, Starlet Ben, Leena Mary, and Ben P. Babu. "Attention and Feature Selection for Automatic SERUsing Utterance and Syllable-Level Prosodic Features." Circuits, Systems, and Signal Processing (2020): 1-29.
Khan, Atreyee, and Uttam Kumar Roy. "Emotion recognition using prosodie and spectral features of speech and Naïve Bayes Classifier." In 2017 international conference on wireless communications, signal processing and networking (WiSPNET), pp. 1017-1021. IEEE, 2017.
Likitha, M. S., Sri Raksha R. Gupta, K. Hasitha, and A. Upendra Raju. "Speech based human emotion recognition using MFCC" In 2017 international conference on wireless communications, signal processing and networking (WiSPNET), pp. 2257-2260. IEEE, 2017.
Sonawane, Anagha, M. U. Inamdar, and Kishor B. Bhangale. "Sound based human emotion recognition using MFCC& multiple SVM." In 2017 International Conference on Information, Communication, Instrumentation and Control (I.C.I.C.I.C.), pp. 1-4. IEEE, 2017.
Bhangale, Kishor B., Prashant Titare, RaosahebPawar, and SagarBhavsar. "Synthetic Speech Spoofing Detection Using MFCCAnd Radial Basis Function SVM." I.O.S.R. Journal of Engineering (I.O.S.R.J.E.N.), Vol. 8, Issue 6, pp.55- 62, 2018.
Renjith, S., and K. G. Manju. "Speech based emotion recognition in Tamil and Telugu using LPCC.andhurst parameters—a comparitive study using KNN and ANN classifiers." In 2017 International conference on circuit, power and computing technologies (I.C.C.P.C.T.), pp. 1-6. IEEE, 2017.
Feraru, Silvia Monica, and Marius Dan Zbancioc. "Emotion recognition in Romanian language using LPC features." In 2013 E-Health and Bioengineering Conference (E.H.B.), pp. 1-4. IEEE, 2013.
Cowie, Roddy, Ellen Douglas-Cowie, Nicolas Tsapatsoulis, George Votsis, StefanosKollias, Winfried Fellenz, and John G. Taylor. "Emotion recognition in human-computer interaction." IEEE Signal processing magazine 18, no. 1 (2001): 32-80.
Li, Xiang, and Xin Li. "SERUsing Novel HHT-TEO Based Features." J.C.P. 6, no. 5 (2011): 989-998.
Drisya, P. S., and Rajeev Rajan. "Significance of teo slope feature in speech emotion recognition." In 2017 International Conference on Networks & Advances in Computational Technologies (NetACT), pp. 438-441. IEEE, 2017.
Bandela, Surekha Reddy, and T. Kishore Kumar. "Stressed SERusing feature fusion of teager energy operator and MFCC" In 2017 8th International Conference on Computing, Communication and Networking Technologies (I.C.C.C.N.T.), pp. 1-5. IEEE, 2017.
Song, P., Zheng, W., Liu, J., Li, J., & Xinran, Z. (2015). A Novel SERMethod via Transfer P.C.A. and Sparse Coding. Chinese Conference on Biometric Recognition, 393-400.
Chen, X., Li, H., Ma, L., Liu, X., & Chen, J. (2015). Teager Mel and P.L.P. Fusion Feature Based Speech Emotion Recognition. Fifth International Conference on Instrumentation and Measurement, Computer, Communication and Control (I.M.C.C.C.), Qinhuangdao, 1109-1114.
Lee, S. (2015). Hybrid Naïve Bayes K-nearest neighbor method implementation on speech emotion recognition. IEEE Advanced Information Technology, Electronic and Automation Control Conference (I.A.E.A.C.), Chongqing, 349-353.
Khan, A. & Roy, U. K. (2017). Emotion recognition using prosodie and spectral features of speech and Naïve Bayes Classifier. International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, 1017-1021.
Sonawane, A., Inamdar, M. U. & Bhangale, K. B. (2017). Sound based human emotion recognition using MFCC& multiple SVM. International Conference on Information, Communication, Instrumentation and Control (I.C.I.C.I.C.), Indore, 1-4.
Song, Peng, and Wenming Zheng. "Feature selection based transfer subspace learning for speech emotion recognition." IEEE Transactions on Affective Computing (2018).
Mao, J., He, Y., & Liu, Z. (2018). SERBased on Linear Discriminant Analysis and Support Vector Machine Decision Tree. 37th Chinese Control Conference (CCC), Wuhan, 5529-5533.
Huang, Y., Xiao, J., Tian, K., Wu, A., & Zhang, G. (2019). Research on Robustness of Emotion Recognition Under Environmental Noise Conditions. IEEE Access, 7, 142009-142021.
Dey, Arijit, Soham Chattopadhyay, Pawan Kumar Singh, Ali Ahmadian, Massimiliano Ferrara, and Ram Sarkar. "A Hybrid Meta-Heuristic Feature Selection Method Using Golden Ratio and Equilibrium Optimization Algorithms for Speech Emotion Recognition." IEEE Access 8 (2020): 200953-200970.
Dr. Govind Shah. (2017). An Efficient Traffic Control System and License Plate Detection Using Image Processing. International Journal of New Practices in Management and Engineering, 6(01), 20 - 25. Retrieved from http://ijnpme.org/index.php/IJNPME/article/view/52
H. Luo and J. Han, "Nonnegative Matrix Factorization Based Transfer Subspace Learning for Cross-Corpus Speech Emotion Recognition," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2047-2060, 2020, doi: 10.1109/TASLP.2020.3006331.
Sönmez, Ye?ím Ülgen, and Asaf Varol. "A SERModel Based on Multi-Level Local Binary and Local Ternary Patterns." IEEE Access 8 (2020): 190784-190796.
Kawade, Rupali, and D. G. Bhalke. "SERBased on Wavelet Packet Coefficients." In ICCCE 2021, pp. 823-828. Springer, Singapore, 2022.
Zehra, Wisha, Abdul RehmanJaved, ZuneraJalil, Habib Ullah Khan, and Thippa Reddy Gadekallu. "Cross corpus multi-lingual SERusing ensemble learning." Complex & Intelligent Systems 7, no. 4 (2021): 1845-1854.
Latif, Siddique, Adnan Qayyum, Muhammad Usman, and Junaid Qadir. "Cross lingual speech emotion recognition: Urdu vs. western languages." In 2018 International Conference on Frontiers of Information Technology (FIT), pp. 88-93. IEEE, 2018.
Zhang, Shiqing, Shiliang Zhang, Tiejun Huang, and Wen Gao. "SERusing deep convolutional neural network and discriminant temporal pyramid matching." IEEE Transactions on Multimedia 20, no. 6 (2017): 1576-1590.
Neumann, Michael. "Cross-lingual and multilingual SERonenglish and french." In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (I.C.A.S.S.P.), pp. 5769-5773. IEEE, 2018.
Zhao, Jianfeng, Xia Mao, and Lijiang Chen. "Learning deep features to recognise speech emotion using merged deep CNN." I.E.T. Signal Processing 12, no. 6 (2018): 713-721.
Chaudhary, A. ., Sharma, A. ., & Gupta, N. . (2023). Designing A Secured Framework for the Steganography Process Using Blockchain and Machine Learning Technology. International Journal of Intelligent Systems and Applications in Engineering, 11(2s), 96–103. Retrieved from https://ijisae.org/index.php/IJISAE/article/view/2512
Ocquaye, Elias NiiNoi, Qirong Mao, Heping Song, Guopeng Xu, and YanfeiXue. "Dual exclusive attentive transfer for unsupervised deep convolutional domain adaptation in speech emotion recognition." IEEE Access 7 (2019): 93847-93857.
Lotfian, Reza, and Carlos Busso. "Curriculum learning for SERfrom crowdsourced labels." IEEE/ACM Transactions on Audio, Speech, and Language Processing 27, no. 4 (2019): 815-826.
Tripathi, Suraj, Abhay Kumar, Abhiram Ramesh, Chirag Singh, and PromodYenigalla. "Deep learning based emotion recognition system using speech features and transcriptions." arXiv preprint arXiv:1906.05681 (2019).
Zhao, Jianfeng, Xia Mao, and Lijiang Chen. "SERusing deep 1D & 2D CNN LSTM networks." Biomedical Signal Processing and Control 47 (2019): 312-323.
Peng, Zhichao, Xingfeng Li, Zhi Zhu, Masashi Unoki, Jianwu Dang, and Masato Akagi. "SERUsing 3D Convolutions and Attention-Based Sliding Recurrent Networks With Auditory Front-Ends." IEEE Access 8 (2020): 16560-16572.
Xiao, Yufeng, Huan Zhao, and Tingting Li. "Learning Class-Aligned and Generalized Domain-Invariant Representations for Speech Emotion Recognition." IEEE Transactions on Emerging Topics in Computational Intelligence (2020).
Ai, Xusheng, Victor S. Sheng, Wei Fang, Charles X. Ling, and Chunhua Li. "Ensemble Learning With Attention-Integrated Convolutional Recurrent Neural Network for Imbalanced Speech Emotion Recognition." IEEE Access 8 (2020): 199909-199919.
Xia, Xiaohan, Dongmei Jiang, and HichemSahli. "Learning Salient Segments for SERUsing Attentive Temporal Pooling." IEEE Access 8 (2020): 151740-151752.
Chen, Gang, Shiqing Zhang, Xin Tao, and Xiaoming Zhao. "SERby Combining A Unified First-order Attention Network with Data Balance." IEEE Access (2020).
H. Zhao, Y. Xiao and Z. Zhang, "Robust Semisupervised Generative Adversarial Networks for SERvia Distribution Smoothness," in IEEE Access, vol. 8, pp. 106889-106900, 2020, doi: 10.1109/ACCESS.2020.3000751.
Guo, Lili, Longbiao Wang, Jianwu Dang, EngSiongChng, and Seiichi Nakagawa. "Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition." Speech Communication 136 (2022): 118-127.
Bhangale, Kishor, and K. Mohanaprasad. "SERUsing Mel Frequency Log Spectrogram and Deep Convolutional Neural Network." In Futuristic Communication and Network Technologies, pp. 241-250. Springer, Singapore, 2022.
Kwon, Soonil. "MLT-DNet: SERusing 1D dilated CNN based on multi-learning trick approach." Expert Systems with Applications 167 (2021a): 114177.
Auma, G., Levi, S., Santos, M., Ji-hoon, P., & Tanaka, A. Predicting Stock Market Trends using Long Short-Term Memory Networks. Kuwait Journal of Machine Learning, 1(3). Retrieved from http://kuwaitjournals.com/index.php/kjml/article/view/136
Kwon, Soonil. "Optimal feature selection based SERusing two?stream deep convolutional neural network." International Journal of Intelligent Systems 36, no. 9 (2021b): 5116-5135.
Neumann, Michael. "Cross-lingual and multilingual SERonenglish and french." In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5769-5773. IEEE, 2018.
Parry, Jack, Dimitri Palaz, Georgia Clarke, Pauline Lecomte, Rebecca Mead, Michael Berger, and Gregor Hofer. "Analysis of Deep Learning Architectures for Cross-Corpus Speech Emotion Recognition." In INTERSPEECH, pp. 1656-1660. 2019.
Liu, Na, Yuan Zong, Baofeng Zhang, Li Liu, Jie Chen, Guoying Zhao, and Junchao Zhu. "Unsupervised cross-corpus SERusing domain-adaptive subspace learning." In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5144-5148. IEEE, 2018.
Su, Bo-Hao, and Chi-Chun Lee. "Unsupervised Cross-Corpus SERUsing a Multi-Source Cycle-GAN." IEEE Transactions on Affective Computing (2022).
Braunschweiler, Norbert, Rama Doddipatla, Simon Keizer, and Svetlana Stoyanchev. "A study on cross-corpus SERand data augmentation." In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 24-30. IEEE, 2021.
Burkhardt, F. ,Paeschke, A. , Rolfes, M. , Sendlmeier, W.F. , Weiss, B. , 2005. A database of German emotional speech.. In: Interspeech. ISCA, pp. 1517–1520
Zhang, J.T.F.L.M. ,Jia, H. , 2008. Design of speech corpus for mandarin text to speech. The Blizzard Challenge 2008 workshop
Kulkarni, L. . (2022). High Resolution Palmprint Recognition System Using Multiple Features. Research Journal of Computer Systems and Engineering, 3(1), 07–13. Retrieved from https://technicaljournals.org/RJCSE/index.php/journal/article/view/35
Iemocap database. 2019. https://sail.usc.edu/iemocap/. Accessed: 2019-05-15.
Surrey audio-visual expressed emotion database. 2019. https://sail.usc.edu/iemocap/ . Accessed: 2019-05-15.
Toronto emotional speech database. 2019. https://tspace.library.utoronto.ca/handle/1807 /24487 . Accessed: 2019-05-15.
Mao, X. , Chen, L. , Fu, L. , 2009. Multi-level SERbased on hmm and ann. In: 2009 W.R.I. World congress on computer science and information engineering, 7. IEEE, pp. 225–229 .
Li, A. , Zheng, F. , Byrne, W. , Fung, P. , Kamm, T. , Liu, Y. , Song, Z. , Ruhi, U. , Venkatara- mani, V. , Chen, X. , 2000. Cass: A phonetically transcribed corpus of mandarin spon- taneous speech. In: Sixth International Conference on Spoken Language Processing .
Li, Y. , Tao, J. , Chao, L. , Bao, W. , Liu, Y. , 2017. Cheavd: a chinese natural emotional au- dio–visual database. J. Ambient Intell. Hum. Comput. 8 (6), 913–924 .
Engberg, I.S. , Hansen, A.V. , Andersen, O. , Dalsgaard, P. , 1997. Design, recording and verification of a Danish emotional speech database. In: Fifth European Conference on Speech Communication and Technology .
Ahammad, D. S. K. H. (2022). Microarray Cancer Classification with Stacked Classifier in Machine Learning Integrated Grid L1-Regulated Feature Selection. Machine Learning Applications in Engineering Education and Management, 2(1), 01–10. Retrieved from http://yashikajournals.com/index.php/mlaeem/article/view/18
Wang, K. , Zhang, Q. , Liao, S. , 2014. A database of elderly emotional speech. In: Proc. Int. Symp. Signal Process. Biomed. EngInformat., pp. 549–553 .
Lee, S. ,Yildirim, S. , Kazemzadeh, A. , Narayanan, S. , 2005. An articulatory study of emo- tional speech production. In: Ninth European Conference on Speech Communication and Technology .
Costantini, G. ,Iaderola, I. , Paoloni, A. , Todisco, M. , 2014. Emovo corpus: an italian emotional speech database. In: International Conference on Language Resources and Evaluation (L.R.E.C. 2014). European Language Resources Association (E.L.R.A.), pp. 3501–3504
Gabriel Santos, Natural Language Processing for Text Classification in Legal Documents , Machine Learning Applications Conference Proceedings, Vol 2 2022.
Martin, O. ,Kotsia, I. , Macq, B. , Pitas, I. , 2006. The enterface'05 audio-visual emo- tion database. In: 22nd International Conference on Data Engineering Workshops (ICDEW'06). IEEE . 8–8.
Mori, S. , Moriyama, T. , Ozawa, S. , 2006. Emotional speech synthesis using subspace con- straints in prosody. In: 2006 IEEE International Conference on Multimedia and Expo., pp. 1093–1096
Liberman, M., Davis, K., Grossman, M., Martey, N., Bell, J., 2002. Emo- tional prosody speech and transcripts. Linguistic Data Consortium. https://catalog.ldc.upenn.edu/LDC2002S28 Accessed: 2019-12-17.
Ringeval, F. ,Sonderegger, A. , Sauer, J. , Lalanne, D. , 2013. Introducing the recola multi- modal corpus of remote collaborative and affective interactions. In: 2013 10th IEEE international conference and workshops on automatic face and gesture recognition (F.G.). IEEE, pp. 1–8 .
McKeown, G. ,Valstar, M. , Cowie, R. , Pantic, M. , Schroder, M. , 2011. The semaine database: annotated multimodal records of emotionally colored conversations be- tween a person and a limited agent. IEEE Trans. Affect. Comput. 3 (1), 5–17 .
Hansen, J.H. ,Bou-Ghazale, S.E. , 1997. Getting started with susas: A speech under simu- lated and actual stress database. In: Fifth European Conference on Speech Communi- cation and technology
Grimm, M. ,Kroschel, K. , Narayanan, S. , 2008. The vera am mittaggerman audio-visual emotional speech database. In: 2008 IEEE international conference on multimedia and expo. IEEE, pp. 865–868
Batliner, A. ,Steidl, S. , Nöth, E. , 2008. Releasing a thoroughly annotated and processed spontaneous emotional database: the fauaibo emotion corpus. In: Proc. of a Satellite Workshop of L.R.E.C., 2008, p. 28
Schuller, B. , Müller, R. , Eyben, F. , Gast, J. , Hörnler, B. , Wöllmer, M. , Rigoll, G. , Höthker, A. , Konosu, H. , 2009. Being bored? recognising natural interest by exten- sive audiovisual integration for real-life application. Image Vis. Comput. 27 (12), 1760–1774
Kossaifi, J. ,Tzimiropoulos, G. , Todorovic, S. , Pantic, M. , 2017. Afew-va database for va- lence and arousal estimation in-the-wild. Image Vis. Comput. 65, 23–36 .
Oflazoglu, C. ,Yildirim, S. , 2013. Recognizing emotion from turkish speech using acoustic features. E.U.R.A.S.I.P. J. Audio Speech Music Process. 2013 (1), 26
Zhalehpour, S. ,Onder, O. , Akhtar, Z. , Erdem, C.E. , 2017. Baum-1: a spontaneous audio-visual face database of affective and mental states. IEEE Trans. Affect. Comput. 8 (3), 300–313