An Innovative Approach for Predicting Software Defects by Handling Class Imbalance Problem
Article Sidebar
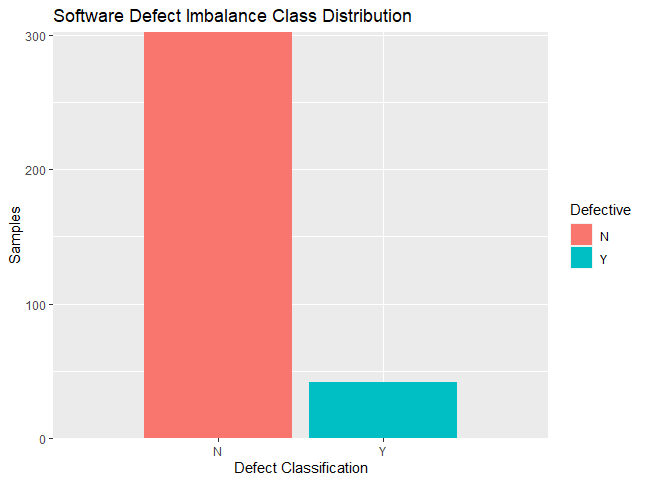
Main Article Content
Abstract
From last decade unbalanced data has gained attention as a major challenge for enhancing software quality and reliability. Due to evolution in advanced software development tools and processes, today’s developed software product is much larger and complicated in nature. The software business faces a major issue in maintaining software performance and efficiency as well as cost of handling software issues after deployment of software product. The effectiveness of defect prediction model has been hampered by unbalanced data in terms of data analysis, biased result, model accuracy and decision making. Predicting defects before they affect your software product is one way to cut costs required to maintain software quality. In this study we are proposing model using two level approach for class imbalance problem which will enhance accuracy of prediction model. In the first level, model will balance predictive class at data level by applying sampling method. Second level we will use Random Forest machine learning approach which will create strong classifier for software defect. Hence, we can enhance software defect prediction model accuracy by handling class imbalance issue at data and algorithm level.
Article Details
References
B. Pes, “Learning from high-dimensional biomedical datasets: The issue of class imbalance,” IEEE Access, vol. 8, pp. 13527–13540, 2020, doi: 10.1109/ACCESS.2020.2966296.
T. M. Khoshgoftaar and E. B. Allen, “Logistic regression modeling of software quality,” Int. J. Reliab. Qual. Saf. Eng., vol. 6, no. 4, pp. 303–317, 1999, doi: 10.1142/S0218539399000292.
R. Akbani, S. Kwek, and N. Japkowicz, “to Imbalanced Datasets,” Eur. Conf. Mach. Learn., pp. 39–50, 2004.
G. E. A. P. A. Batista, R. C. Prati, and M. C. Monard, “A study of the behavior of several methods for balancing machine learning training data,” ACM SIGKDD Explor. Newsl., vol. 6, no. 1, pp. 20–29, 2004, doi: 10.1145/1007730.1007735.
L. Breiman, “Random Forests,” Mach. Learn. 45, 5-32., pp. 542–545, 2001, doi: 10.1109/ICCECE51280.2021.9342376.
L. Breiman, “Bagging predictors,” Mach. Learn., vol. 24, no. 2, pp. 123–140, 1996, doi: 10.1007/bf00058655.
J. Ha, M. Kambe, and J. Pe, Data Mining: Concepts and Techniques. 2011. doi: 10.1016/C2009-0-61819-5.
H. Krasner, “Quality Software A 2018 Report,” Consort. IT Softw. Qual., 2018.
R. S. Suryawanshi, A. Kadam, and D. R. Anekar, “Software defect prediction: A survey with machine learning approach,” Int. J. Adv. Sci. Technol., vol. 29, no. 5, pp. 330–335, 2020.
F. Akiyama, “An Example of Software System Debugging.,” Int. Fed. Inf. Process. Congr., vol. 71, pp. 353–359, 1971, Accessed: Mar. 03, 2020. [Online]. Available: https://dblp.org/rec/conf/ifip/Akiyama71
A. Ihara et al., “An investigation on software bug-fix prediction for open source software projects - A case study on the eclipse project,” Proc. - Asia-Pacific Softw. Eng. Conf. APSEC, vol. 2, pp. 112–119, 2012, doi: 10.1109/APSEC.2012.86.
Q. Yu, J. Qian, S. Jiang, Z. Wu, and G. Zhang, “An Empirical Study on the Effectiveness of Feature Selection for Cross-Project Defect Prediction,” IEEE Access, vol. 7, pp. 35710–35718, 2019, doi: 10.1109/ACCESS.2019.2895614.
N. K. Nagwani and S. Verma, “Predicting expert developers for newly reported bugs using frequent terms similarities of bug attributes,” Int. Conf. ICT Knowl. Eng., pp. 113–117, 2011, doi: 10.1109/ICTKE.2012.6152388.
S. S. Rathore and A. Gupta, “Investigating object-oriented design metrics to predict fault-proneness of software modules,” 2012 CSI 6th Int. Conf. Softw. Eng. CONSEG 2012, 2012, doi: 10.1109/CONSEG.2012.6349484.
P. Anand, “An approach for feature-level bug prediction using test cases,” 2015 Int. Conf. Adv. Comput. Commun. Informatics, ICACCI 2015, pp. 1111–1117, 2015, doi: 10.1109/ICACCI.2015.7275759.
S. Puranik, P. Deshpande, and K. Chandrasekaran, “A Novel Machine Learning Approach for Bug Prediction,” Procedia Comput. Sci., vol. 93, no. September, pp. 924–930, 2016, doi: 10.1016/j.procs.2016.07.271.
S. S. Rathore and S. Kumar, “Linear and non-linear heterogeneous ensemble methods to predict the number of faults in software systems,” Knowledge-Based Syst., vol. 119, pp. 232–256, 2017, doi: 10.1016/j.knosys.2016.12.017.
J. Zheng, X. Wang, D. Wei, B. Chen, and Y. Shao, “A Novel Imbalanced Ensemble Learning in Software Defect Predication,” IEEE Access, vol. 9, pp. 86855–86868, 2021, doi: 10.1109/ACCESS.2021.3072682.
R. Malhotra and K. Lata, “Improving Software Maintainability Predictions using Data Oversampling and Hybridized Techniques,” pp. 1–7, 2020, doi: 10.1109/cec48606.2020.9185809.
Farhad Khoshbakht, Atena Shiranzaei, S. M. K. Quadri. (2023). Design & Develop: Data Warehouse & Data Mart for Business Organization. International Journal of Intelligent Systems and Applications in Engineering, 11(3s), 260–265. Retrieved from https://ijisae.org/index.php/IJISAE/article/view/2682
S. S. Rathore and S. Kumar, “An approach for the prediction of number of software faults based on the dynamic selection of learning techniques,” IEEE Trans. Reliab., vol. 68, no. 1, pp. 216–236, 2019, doi: 10.1109/TR.2018.2864206.
Prof. Barry Wiling. (2017). Monitoring of Sona Massori Paddy Crop and its Pests Using Image Processing. International Journal of New Practices in Management and Engineering, 6(02), 01 - 06. https://doi.org/10.17762/ijnpme.v6i02.54
T. T. Khuat and M. H. Le, “Evaluation of Sampling-Based Ensembles of Classifiers on Imbalanced Data for Software Defect Prediction Problems,” SN Computer Science, vol. 1, no. 2. 2020. doi: 10.1007/s42979-020-0119-4.
S. Goyal, “Handling Class-Imbalance with KNN (Neighbourhood) Under-Sampling for Software Defect Prediction,” Artificial Intelligence Review, vol. 55, no. 3. pp. 2023–2064, 2022. doi: 10.1007/s10462-021-10044-w.
M. Gan, Z. Yücel, and A. Monden, “Neg/pos-Normalized Accuracy Measures for Software Defect Prediction,” IEEE Access, vol. 10, no. November, pp. 134580–134591, 2022, doi: 10.1109/ACCESS.2022.3232144.
P. Soltanzadeh and M. Hashemzadeh, “RCSMOTE: Range-Controlled synthetic minority over-sampling technique for handling the class imbalance problem,” Inf. Sci. (Ny)., vol. 542, pp. 92–111, 2021, doi: 10.1016/j.ins.2020.07.014.
F. Thabtah, S. Hammoud, F. Kamalov, and A. Gonsalves, “Data imbalance in classification: Experimental evaluation,” Inf. Sci. (Ny)., vol. 513, pp. 429–441, 2020, doi: 10.1016/j.ins.2019.11.004.
M. Shepperd, Q. Song, Z. Sun, and C. Mair, “Data quality: Some comments on the NASA software defect datasets,” IEEE Trans. Softw. Eng., vol. 39, no. 9, pp. 1208–1215, 2013.