A Robust Deep Model for Improved Categorization of Legal Documents for Predictive Analytics
Article Sidebar
Main Article Content
Abstract
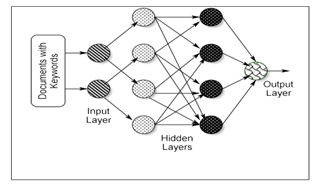
Predictive legal analytics is a technology used to predict the chances of successful and unsuccessful outcomes in a particular case. Predictive legal analytics is performed through automated document classification for facilitating legal experts in their classification of court documents to retrieve and understand the details of specific legal factors from legal judgments for accurate document analysis. However, extracting these factors from legal texts document is a time-consuming process. In order to facilitate the task of classifying documents, a robust method namely Distributed Stochastic Keyword Extraction based Ensemble Theil-Sen Regressive Deep Belief Reweight Boost Classification (DSKE-TRDBRBC) is proposed. The DSKE-TRDBRBC technique consists of two major processes namely Keyword Extraction and Classification. At first, the t-distributed stochastic neighbor embedding technique is applied to DSKE-TRDBRBC for keyword extraction. This in turn minimizes the time consumption for document classification. After that, the Ensemble Theil-Sen Regressive Deep Belief Reweight Boosting technique is applied for document classification. The Ensemble boosting algorithm initially constructs’ set of Theil-Sen Regressive Deep Belief neural networks to classify the input legal documents. Then the results of the Deep Belief neural network are combined to built a strong classifier by reducing the error. This aids in improving the classification accuracy. The proposed method is experimentally evaluated with various metrics such as F-measure , recall, accuracy, precision, , and computational time. The experimental results quantitatively confirm that the proposed DSKE-TRDBRBC technique achieves better accuracy with lowest computation time as compared to the conventional approaches.
Article Details
References
Donghong Ji, Peng Tao, Hao Fei, Yafeng Ren, “An end-to-end joint model for evidence information extraction from court record document”, Information Processing & Management, Elsevier,Volume 57, Issue 6, 2020, Pages 1-14
Dezhao Song, Andrew Vold, Kanika Madan, Frank Schilder, “Multi- label legal document classification: A deep learning-based approach with label-attention and domain-specific pre-training”, Information Systems, Elsevier, 2021, Pages 1-12
Emilio Sulis, Llio Humphreys, Fabiana Vernero, Ilaria Angela Amantea, Davide Audrito, Luigi Di Caro, “Exploiting co-occurrence networks for classification of implicit inter-relationships in legal texts”, Information Systems, Elsevier, 2021, Pages 1-12.
Weizhong Zhao, Dandan Fang, Jinyong Zhang, Yao Zhao, Xiaowei Xu, Xingpeng Jiang, Xiaohua Hu, Tingting He, “An effective framework for semistructured document classification via hierarchical attention model”, International Journal of intelligent system, Wiley, Volume 36, Issue 9, 2021, Pages 5161-5183
Kshitij Tripathi, Rajendra G. Vyas, and Anil K. Gupta, “Document Classification Using Artificial Neural Network”, Asian Journal of Computer Science and Technology, Volume 8 Issue 2, 2019, Pages 55-58
Peng Yan, Linjing Li, Miaotianzi Jin, Daniel Zeng, “Quantum probability-inspired graph neural network for document representation and classification”, Neurocomputing, Elsevier,Volume 445, 2021, Pages 276-286
Wenlong Fu, Bing Xue, Xiaoying Gao, Mengjie Zhang, “Output- based transfer learning in genetic programming for document classification”, Knowledge-Based Systems, Elsevier, Volume 212, 2021, Pages 1-11
Guodong Li, Zhe Wang, Yinglong Ma, “Combining Domain Knowledge Extraction With Graph Long Short-Term Memory for Learning Classification of Chinese Legal Documents”, IEEE Access,Volume 7, 2019, Pages 139616 – 139627
Muhammad Pervez Akhter, Zheng Jiangbin, Irfan Raza Naqvi, Mohammed Abdelmajeed, Atif Mehmood, and Muhammad Tariq Sadiq, “Document-Level Text Classification Using Single-Layer Multisize Filters Convolutional Neural Network”, IEEE Access,Volume 8, 2020, Pages 42689 – 42707
Zenun Kastrati, Ali Shariq Imran, Sule Yildirim Yayilgan, “The impact of deep learning on document classification using semantically rich representations”, Information Processing & Management, Elsevier, Volume 56, Issue 5, 2019, Pages 1618-1632
Yingren Huang, Jiaojiao Chen, Shaomin Zheng, Yun Xue, Xiaohui Hu, “Hierarchical multi?attention networks for document classification”, International Journal of Machine Learning and Cybernetics, Springer, Volume 12, Issue 3, 2021
Shuo Yang, Ran Wei, Jingzhi Guo, Hengliang Tan, “Chinese semantic document classification based on strategies of semantic similarity computation and correlation analysis”, Journal of Web Semantics, Elsevier, Volume 63, 2020, Pages 1-15
Pengfei Li, Kezhi Maoa, Yuecong Xu, Qi Li, Jiaheng Zhang, “Bag- of-Concepts representation for document classification based on automatic knowledge acquisition from probabilistic knowledge base”, Knowledge-Based Systems, Elsevier, Volume 193, 2020, Pages 1-14
Süleyman Eken, Houssem Menhour, Kübra Köksal, “DoCA: A Content-Based Automatic Classification System Over Digital Documents”, IEEE Access, Volume 7, 2019, Pages 97996 – 98004
Veena Hosamani,H S Vimala, “Data Science: Prediction and Analysis of Data using Multiple Classifier System”, International Journal of Computer Engineering in Research Trends, Volume 5, Issue 12, 2019, Page(s): 216- 222.
Deepa Anand, Rupali Wagh, “Effective deep learning approaches for summarization of legal texts”, Journal of King Saud University -Computer and Information Sciences, Elsevier, 2019, Pages 1-18
Silvana Castano, Mattia Falduti, Alfio Ferrara, Stefano Montanelli, A knowledge-centered framework for exploration and retrieval of legal documents”, Information Systems, Elsevier, 2021, Pages 1-14
Y.Yashasree, K.Venkatesh Sharma “Creditcard Fraud Detection and Classification Using Machine Learning Based Classifiers”, International Journal of Computer Engineering in Research Trends, Volume 7, Issue 9, 2020, Page(s): 1- 8.
Ahmad Muqeem Sheri, Muhammad Aasim Rafique, Malik Tahir Hassan, Khurum Nazir Junejo, Moongu Jeon Gwangju, South Korea, “Boosting Discrimination Information Based Document Clustering Using Consensus and Classification”, IEEE Access, Volume 7, 2019,Pages 78954 – 78962
Hao Peng, Jianxin Li, Senzhang Wang, Lihong Wang, Qiran Gong, Renyu Yang, Bo Li, Lifang He, and Philip S. Yu, “Hierarchical Taxonomy-Aware and Attentional Graph Capsule RCNNs for Large- Scale Multi-Label Text Classification”, IEEE Transactions on Knowledge and Data Engineering, Volume 33, Issue 6, 2021, Pages 2505 – 2519