An Oversampling Mechanism for Multimajority Datasets using SMOTE and Darwinian Particle Swarm Optimisation
Article Sidebar
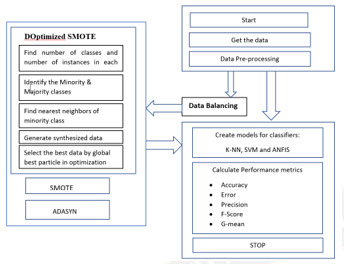
Main Article Content
Abstract
Data skewness continues to be one of the leading factors which adversely impacts the machine learning algorithms performance. An approach to reduce this negative effect of the data variance is to pre-process the former dataset with data level resampling strategies. Resampling strategies have been seen in two forms, oversampling and undersampling. An oversampling strategy is proposed in this article for tackling multiclass imbalanced datasets. This proposed approach optimises the state-of-the-art oversampling technique SMOTE with the Darwinian Particle Swarm Optimization technique. This proposed method DOSMOTE generates synthetic optimised samples for balancing the datasets. This strategy will be more effective on multimajority datasets. An experimental study is performed on peculiar multimajority datasets to measure the effectiveness of the proposed approach. As a result, the proposed method produces promising results when compared to the conventional oversampling strategies.
Article Details
References
W. Liu et al., “A comprehensive active learning method for multiclass imbalanced data streams with concept drift,” Knowledge-Based Syst., vol. 215, p. 106778, 2021.
M. Koziarski and M. Wozniak, “CCR: A combined cleaning and resampling algorithm for imbalanced data classification,” Int. J. Appl. Math. Comput. Sci., vol. 27, no. 4, pp. 727–736, 2017, doi: 10.1515/amcs-2017-0050.
S. S. Yadav and G. P. Bhole, “Learning from Imbalanced Data in Classification,” Int. J. Recent Technol. Eng., vol. 8, no. 5, pp. 1907–1916, 2020.
R. M. Mathew and R.Gunasundari, “A review on handling multiclass imbalanced data classification in education domain,” in 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE, 2021, pp. 752–755, doi: 10.1109/ICACITE51222.2021.9404626.
S. Wang and X. Yao, “Multiclass imbalance problems: Analysis and potential solutions,” IEEE Trans. Syst. Man, Cybern. Part B Cybern., vol. 42, no. 4, pp. 1119–1130, 2012, doi: 10.1109/TSMCB.2012.2187280.
Sun et al. (2009). Classification of imbalanced data: A review, International Journal of Pattern Recognition and Artificial Intelligence 23(04): 687–719.
L´opez et al. (2013). An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics, Information Sciences 250: 113–141.
M. Galar et al., “EUSBoost: Enhancing ensembles for highly imbalanced data-sets by evolutionary undersampling,” Pattern Recognit., vol. 46, no. 12, pp. 3460–3471, 2013.
Wang, S. and Yao, X. (2012). Multiclass imbalance problems: Analysis and potential solutions, IEEE Transactions on Systems, Man, and Cybernetics B: Cybernetics 42(4): 1119–1130
Zhang et al. (2016). Empowering one-vs-one decomposition with ensemble learning for multi-class imbalanced data, Knowledge-Based Systems 106: 251–263.
B. Krawczyk, “Learning from imbalanced data: open challenges and future directions,” Prog. Artif. Intell., vol. 5, no. 4, pp. 221–232, 2016.
Stefanowski, J. (2016). Dealing with data difficulty factors while learning from imbalanced data, in S. Matwin and J. Mielniczuk (Eds.), Challenges in Computational Statistics and Data Mining, Springer, Heilderberg, pp. 333–363.
Chawla et al. (2002). SMOTE: Synthetic minority over-sampling technique, Journal of Artificial Intelligence Research 16: 321–357.
Chawla et al. (2003). SMOTEBoost: Improving prediction of the minority class in boosting, European Conference on Principles of Data Mining and Knowledge Discovery, Cavtat/Dubrovnik, Croatia, pp. 107–119.
Bunkhumpornpat et al. (2009). Safe-level-SMOTE: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem, Pacific-Asia Conference on Knowledge Discovery and Data Mining, Bangkok, Thailand, pp. 475–482.
Napiera?a, K. and Stefanowski, J. (2012). Identification of different types of minority class examples in imbalanced data, International Conference on Hybrid Artificial Intelligence Systems, Salamanca, Spain, pp. 139–150.
He, H et al. (2008). ADASYN: Adaptive synthetic sampling approach for imbalanced learning, 2008 IEEE International Joint Conference on Neural Networks (IEEEWorld Congress on Computational Intelligence), Hong Kong, China, pp. 1322–1328.
Stefanowski, J. and Wilk, S. (2008). Selective pre-processing of imbalanced data for improving classification performance, International Conference on Data Warehousing and Knowledge Discovery, Turin, Italy, pp. 283–292.
Laurikkala, J. (2001). Improving identification of difficult small classes by balancing class distribution, Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, pp. 63–66.
Garcia, S. and Herrera, F. (2009). Evolutionary undersampling for classification with imbalanced datasets: Proposals and taxonomy, Evolutionary Computation 17(3): 275–306.
F. Fernández-Navarro et al., “A dynamic over-sampling procedure based on sensitivity for multi-class problems,” Pattern Recognit., vol. 44, no. 8, pp. 1821–1833, 2011, doi: 10.1016/j.patcog.2011.02.019.
Tomek, I. (1976). Two modifications of CNN, IEEE Transactions on Systems, Man, and Cybernetics 6(11): 769–772.
Wilson, D.L. (1972). Asymptotic properties of nearest neighbor rules using edited data, IEEE Transactions on Systems, Man, and Cybernetics 2(3): 408–421.
J. Tillett et al., “Darwinian particle swarm optimization,” Proc. 2nd Indian Int. Conf. Artif. Intell. IICAI 2005, pp. 1474–1487, 2005.
Kennedy J. and Eberhart R. C. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks; Institute of Electrical and Electronics Engineers. Vol. 4. 1995. pp. 1942–1948. DOI: 10.1109/ICNN.1995.488968
Xi-Bin Dong Xian-Bing Meng Zhi-Wen Yu Philip Chen Guo-Qiang Han, “A PSO-optimized Oversampling Method for Imbalance Classification”, Key-Area Research and Development Program of Guangdong Province No. 2018B010107002,2020
J. Alcalá-Fdez et al., “KEEL: A software tool to assess evolutionary algorithms for data mining problems,” Soft Comput., vol. 13, no. 3, pp. 307–318, 2009, doi: 10.1007/s00500-008-0323-y.
J. Alcalá-Fdez et al., “KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework,” J. Mult. Log. Soft Comput., vol. 17, no. 2–3, pp. 255–287, 2011.
Rose Mary Mathew, Dr. R. Gunasundari. (2021). An Experimental Study on The Effect of Resampling Techniques in Multiclass Imbalanced Data in Learning Sector. Design Engineering, 16216-16234. Available at http://www.thedesignengineering.com/index.php/DE/article/view/6768
Hosseini, M. S., & Zekri, M. (2012). Review of Medical Image Classification using the Adaptive Neuro-Fuzzy Inference System. Journal of medical signals and sensors, 2(1), 49–60.