An Approach for Mining Top-k High Utility Item Sets (HUI)
Article Sidebar
Main Article Content
Abstract
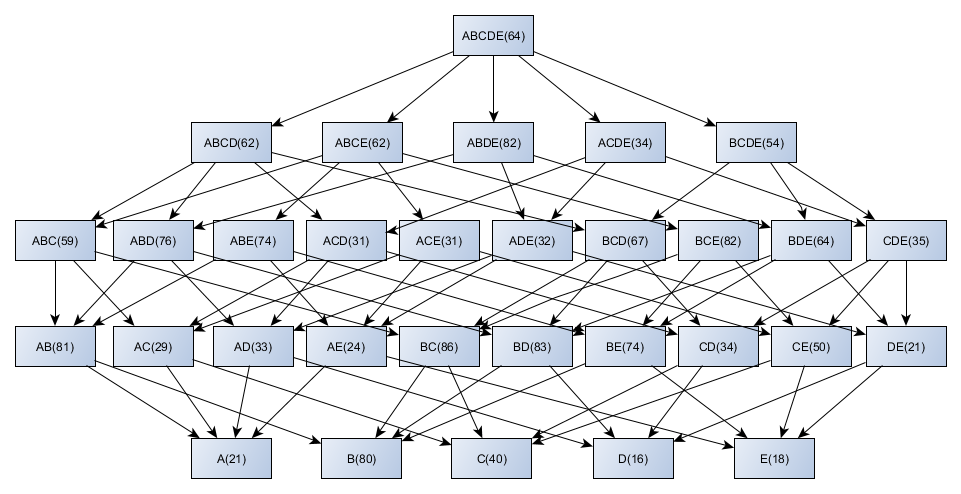
Itemsets have been extracted by utilising high utility item (HUI) mining, which provides more benefits to the consumer. This could be one of the significant domains in data mining and be resourceful for several real-time implementations. Even though modern HUI mining algorithms may identify item sets that meet the minimum utility threshold, However, fixing the minimum threshold utility value has not been a simple task, and often it is intricate for the consumers when we keep the minimum utility value low. It might generate a massive amount of itemsets, and when the value is at its maximum, it might provide a smaller amount of itemsets. To avoid these issues, top-k HUI mining, where k represents the number of HUIs to be identified, has been proposed. Further, in this manuscript, the authors projected an algorithm called the top-k exact utility (TKEU) algorithm, which works without computing and comparing transaction weighted utilisation (TWU) values and deliberates the individual utility item values for deriving the top-k HUI. The datasets are pre-processed by the proposed algorithm to lessen the system memory space and to provide optimal outcomes for condensed datasets.
Article Details
References
Efficient Algorithms for Mining Top-K High Utility Itemsets using data stream, Vincent S. Tseng, Senior Member, Cheng WeiWu, Philippe Fournier-Viger, Philip S. Yu, Fellow, IEEE2016.
Efficient Algorithms for Mining High Utility Transactional Databases, Bai-En Shie, Philip S. Yu,Fellow, Cheng-Wei Wu, and Vincent S. Tseng, IEEE transactions on knowledge and data engineering, vol. 25,no. 8, august 2017.
Dawar, S., Sharma, V., & Goyal, V. (2017). Mining top-k high-utility itemsets from a data stream under sliding window model. Applied Intelligence, 47(4), 1240-1255.
J. Yin, Z. Zheng, L. Cao, Y. Song, and W. Wei, “Dynamic approach for mining top-k high utility items using stemming and collaborative filtering algorithms ” in Proc. IEEE Int. Conf. Data Mining, 2018, pp. 1259–1264.
Nguyen, L. T., Vu, V. V., Lam, M. T., Duong, T. T., Manh, L. T., Nguyen, T. T., ... & Fujita, H. (2019). An efficient method for mining high utility closed itemsets. Information Sciences, 495, 78-99.
Efficient Algorithms for Mining Top-K High Utility Itemsets using data stream, Vincent S. Tseng, Senior Member, Cheng WeiWu, Philippe Fournier-Viger, Philip S. Yu, Fellow, IEEE2015.
Efficient Algorithms for Mining High Utility Transactional Databases, Bai-En Shie, Philip S. Yu,Fellow, Cheng-Wei Wu, and Vincent S. Tseng, IEEE transactions on knowledge and data engineering, vol. 25,no. 8, august 2013.
Fournier-Viger, P., Zhang, Y., Lin, J. C. W., Dinh, D. T., & Le, H. B. (2018). Mining correlated high-utility itemsets using various measures. Logic J IGPL Google Scholar.
Fournier-Viger P, Wu C-W, Zida S, Tseng VS (2014b) FHM: faster high-utility itemset mining using estimated utility cooccurrence pruning. Springer International Publishing, Cham, pp 83–92.
Fournier-Viger P, Zida S (2015) Foshu: faster on-shelf high utility itemset mining – with or without negative unit profit. In: Proceedings of the 30th annual ACM symposium on applied computing, SAC ’15. ACM, New York, pp 857–864.
Y.Usha Sree,P.Ragha Vardhani (2015). Pattern Finding in Large Datasets with Big Data Analytics Mechanism. International Journal of Computer Engineering In Research Trends, 2(5), 359-364.
P.M. Gavali1(2018). Investigation of Mining Association Rules on XML Document. International Journal of Computer Engineering In Research Trends, 5(1), 12-15.
B.Senthilkumaran , K.Thangadurai(2017). A Comparative Study of Discovering Frequent Subgraphs – Approaches and Techniques. International Journal of Computer Engineering In Research Trends, 4(1), 41-45.