Hybrid Cloud-Based Privacy Preserving Clustering as Service for Enterprise Big Data
Article Sidebar
Main Article Content
Abstract
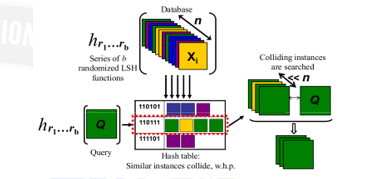
Clustering as service is being offered by many cloud service providers. It helps enterprises to learn hidden patterns and learn knowledge from large, big data generated by enterprises. Though it brings lot of value to enterprises, it also exposes the data to various security and privacy threats. Privacy preserving clustering is being proposed a solution to address this problem. But the privacy preserving clustering as outsourced service model involves too much overhead on querying user, lacks adaptivity to incremental data and involves frequent interaction between service provider and the querying user. There is also a lack of personalization to clustering by the querying user. This work “Locality Sensitive Hashing for Transformed Dataset (LSHTD)” proposes a hybrid cloud-based clustering as service model for streaming data that address the problems in the existing model such as privacy preserving k-means clustering outsourcing under multiple keys (PPCOM) and secure nearest neighbor clustering (SNNC) models, The solution combines hybrid cloud, LSHTD clustering algorithm as outsourced service model. Through experiments, the proposed solution is able is found to reduce the computation cost by 23% and communication cost by 6% and able to provide better clustering accuracy with ARI greater than 4.59% compared to existing works.
Article Details
References
Zobaed, S., Gottumukkala, R.N., & Salehi, M. (2020). Privacy-Preserving Clustering of Unstructured Big Data for Cloud-Based Enterprise Search Solutions. ArXiv, abs/2005.11317.
Wei Fu and Patrick O Perry. Estimating the number of clusters using cross-validation. Journal of Computational and Graphical Statistics, pages 1–12, January 2019.
Angel Latha Mary and KR Shankar Kumar. A density based dynamic data clustering algorithm based on incremental dataset. Journal of Computer Science, 8(5):656–664, February 2012
Hong Rong, Huimei Wang, Jian Liu, Jialu Hao, Ming Xian, "Privacy-Preserving -Means Clustering under Multiowner Setting in Distributed Cloud Environments", Security and Communication Networks, vol. 2017, Article ID 3910126, 19 pages, 2017
J. Yuan and Y. Tian, "Practical Privacy-Preserving MapReduce Based K-Means Clustering Over Large-Scale Dataset" in IEEE Transactions on Cloud Computing, vol. 7, no. 02, pp. 568-579, 2019
F.-Y. Rao, B. K. Samanthula, E. Bertino, X. Yi, and D. Liu, “Privacy-preserving and outsourced multi-user k-means clustering,” in Proceedings of the 1st IEEE International Conference on Collaboration and Internet Computing, CIC 2015, pp. 80–89, October 2015.
Ying Zou, Zhen Zhao, Sha Shi, Lei Wang, Yunfeng Peng, Yuan Ping, Baocang Wang, "Highly Secure Privacy-Preserving Outsourced k-Means Clustering under Multiple Keys in Cloud Computing", Security and Communication Networks, vol. 2020
Q. Yu, Y. Luo, C. Chen, and X. Ding, “Outlier-eliminated k-means clustering algorithm based on differential privacy preservation,” Applied Intelligence, vol. 45, no. 4, pp. 1179–1191, 2016.
T. Shang, Z. Zhao, Z. Guan, and J. Liu, “A DP canopy k-means algorithm for privacy preservation of hadoop platform,” in Proceedings of the CSS 2017, Lecture Notes in Computer Science, vol. 10581, pp. 189–198, Springer, Xi’an, China, October 2017
H. Rong, H. Wang, J. Liu, J. Hao, and M. Xian, “Outsourced k-means clustering over encrypted data under multiple keys in spark framework,” in Proceedings of the SecureComm 2017, Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, vol. 238, pp. 67–87, Springer, Niagara Falls, ON, Canada, October 2017.
Q. Zhang, L. T. Yang, Z. Chen, and P. Li, “Pphopcm: privacy-preserving high-order possibilistic c-means algorithm for big data clustering with cloud computing,” IEEE Transactions on Big Data, 2017.
N. Almutairi, F. Coenen, and K. Dures, “K-means clustering using homomorphic encryption and an updatable distance matrix: secure third party data clustering with limited data owner interaction,” in Proceedings of the DaWaK 2017, Lecture Notes in Computer Science, vol. 10440, pp. 274–285, Springer, Lyon, France, August 2017.
K.-P. Lin, “Privacy-preserving kernel k-means clustering outsourcing with random transformation,” Knowledge and Information Systems, vol. 49, no. 3, pp. 885–908, 2016
Z. Gheid and Y. Challal, “Efficient and privacy-preserving k-means clustering for big data mining,” in Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, pp. 791–798, IEEE, Tianjin, China, August 2016.
Hu Xiaoyi,Lu Liping,"Privacy-Preserving K-Means Clustering Upon Negative Databases",Springer International Publishing,2018
D. Zhao et al., "A Fine-grained Privacy-preserving k-means Clustering Algorithm Upon Negative Databases," 2019 IEEE Symposium Series on Computational Intelligence (SSCI), 2019, pp. 1945-1951
Dongdong Zhao, Xiaoyi Hu, Shengwu Xiong, Jing Tian,"k-means clustering and kNN classification based on negative databases",Applied Soft Computing,2021
Brandão, André & Mendes, Ricardo & Vilela, Joao. (2021). Efficient Privacy Preserving Distributed K-Means for Non-IID Data. 10.1007/978-3-030-74251-5_35.
Jiang, Z.L., Guo, N., Jin, Y., Lv, J., Wu, Y., Liu, Z., Fang, J., Yiu, S.M., Wang, X.: Efficient two-party privacy-preserving collaborative k-means clustering protocol supporting both storage and computation outsourcing. Information Sciences 518, 168–180 (2020)
Almutairi, N., Coenen, F., & Dures, K. (2018). Third Party Data Clustering Over Encrypted Data Without Data Owner Participation: Introducing the Encrypted Distance Matrix. DaWaK.
X. Xu and X. Zhao, "A Framework for Privacy-Aware Computing on Hybrid Clouds with Mixed-Sensitivity Data," 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, 2015
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S Mirrokni. 2004. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on Computational geometry. 253–262.
Mayank Bawa, Tyson Condie, and Prasanna Ganesan. 2005. LSH forest: self-tuning indexes for similarity search. In Proceedings of the 14th international conference on World Wide Web. 651–660
Junhao Gan, Jianlin Feng, Qiong Fang, and Wilfred Ng. 2012. Locality-sensitive hashing scheme based on dynamic collision counting. In Proceedings of the 2012 ACM SIGMOD international conference on management of data. 541–552.
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. 2015. Query-aware locality-sensitive hashing for approximate nearest neighbor search. Proceedings of the VLDB Endowment 9, 1 (2015), 1–12
Wanqi Liu, Hanchen Wang, Ying Zhang, Wei Wang, and Lu Qin. 2019. I-LSH: I/O efficient c-approximate nearest neighbor search in highdimensional space. In 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 1670–167
Yifang Sun, Wei Wang, Jianbin Qin, Ying Zhang, and Xuemin Lin. 2014. SRS: solving c-approximate nearest neighbor queries in high dimensional euclidean space with a tiny index. Proceedings of the VLDB Endowment (2014).
McConville, R., Cao, X., Liu, W., & Miller, P. (2016). Accelerating Large Scale Centroid-based Clustering with Locality Sensitive Hashing. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE) (pp. 649-660). Institute of Electrical and Electronics Engineers (IEEE).
C. Opri?a, M. Checiche? and A. N?ndrean, "Locality-sensitive hashing optimizations for fast malware clustering," 2014 IEEE 10th International Conference on Intelligent Computer Communication and Processing (ICCP), 2014, pp. 97-104
Jafari, Omid & Maurya, Preeti & Nagarkar, Parth & Islam, Khandker & Crushev, Chidambaram. (2021). A Survey on Locality Sensitive Hashing Algorithms and their Applications.
Khader, Mariam & Al-Naymat, Ghazi. (2020). Density-based Algorithms for Big Data Clustering Using MapReduce Framework: A Comprehensive Study. ACM Computing Surveys. 53. 1-38. 10.1145/3403951.
Veeraiah N, Krishna BT. Intrusion detection based on piecewise fuzzy C-means clustering and fuzzy Naïve Bayes rule. Multimedia Research. 2018 Oct;1(1):27-3.
https://archive.ics.uci.edu/ml/datasets/
M. Hahsler, M. Bolanos, and J. Forrest, stream: Infrastructure for Data Stream Mining, 2015, R package version 1.2-2.
N.X. Vinh, J. Epps, J. Bailey, Information theoretic measures for clustering’s comparison: is a correction for chance necessary? in: Proceedings of the 26th Annual International Conference on Machine Learning, ACM, 2009, pp. 1073–1080.
Rand, W. M. (1971) Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66, 846–850
L. Wan, W.K. Ng, X.H. Dang, P.S. Yu, K. Zhang, Density-based clustering of data streams at multiple resolutions, ACM Trans. Knowl. Discov. Data 3 (3) (2009) 49–50.
Xu, Ji & Wang, Guoyin & Li, Tianrui & Deng, Weihui & Guanglei, Gou. (2017). Fat Node Leading Tree for Data Stream Clustering with Density Peaks. Knowledge-Based Systems. 120. 99-117. 10.1016/j.knosys.2016.12.025.