Text-Independent Automatic Dialect Recognition of Marathi Language using Spectro-Temporal Characteristics of Voice
Article Sidebar
Main Article Content
Abstract
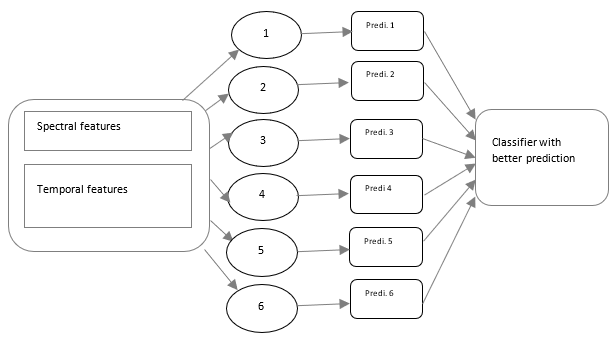
Text-independent dialect recognition system is proposed in this paper for Marathi language. India is rich in language varieties. Each language in turn has its unique dialect variations. Maharashtra has Marathi as official language and for Goa it is a co-official language . In literature there are very few studies available for Indian language recognition and then their respective dialect recognition. So research work available for regional languages such as Marathi is extremely limited. As a part of research work, an attempt is made to generate a case study of a low resourced Marathi language dialect recognition system. The study was carried out using Marathi speech data corpus provided by Linguistic Data Consortium for Indian Language (LDC- IL). This corpus includes four major dialects of Marathi speakers. The efficiency and performance evaluation of the explored spectral (rhythmic) and temporal features are carried out to perform classification tasks. We investigated the performance of six different classifiers; K-nearest neighbor (KNN), Naïve Bayes (NB), Support Vector Machine (SVM), Decision Tree (DT) classifier , Stochastic Gradient Descent (SGD) classifier and Ridge Classifier (RC). Experimental results have demonstrated that the RC classifier worked well with 84.24% of accuracy for fifteen spectral and temporal features. With twelve MFCCs it has been observed that SGD has outperformed among all classifiers with accuracy of 80.63%. For further study, a prominent feature subset as a part of dimensionality reduction has been identified using chi square, mutual information and ANOVA-f test. In this chi-square based feature extraction method has proven to be the best over over mutual information and ANOVA f-test.
Article Details
References
Abro, S., Sarang Shaikh, Z. A., Khan, S., Mujtaba, G., & Khand, Z. H. (2020). Automatic hate speech detection using machine learning: A comparative study. Machine Learning, 10(6).
Alexandrou, A. M., Saarinen, T., Kujala, J., & Salmelin, R. (2016). A multimodal spectral approach to characterize rhythm in natural speech. The Journal of the Acoustical Society of America, 139(1), 215-226.
Ali, A., Dehak, N., Cardinal, P., Khurana, S., Yella, S. H., Glass, J., ... & Renals, S. (2015). Automatic dialect detection in arabic broadcast speech. arXiv preprint arXiv:1509.06928.
Bansod, N. S., Dadhade, S. B., Kawathekar, S. S., & Kale, K. V. (2014, March). Speaker Recognition using Marathi (Varhadi) Language. In 2014 International Conference on Intelligent Computing Applications (pp. 421-425). IEEE.
Biadsy, F. (2011). Automatic dialect and accent recognition and its application to speech recognition. Columbia University.
Chittaragi, N. B., Limaye, A., Chandana, N. T., Annappa, B., & Koolagudi, S. G. (2019). Automatic text-independent Kannada dialect identification system. In Information Systems Design and Intelligent Applications (pp. 79-87). Springer, Singapore.
Elfeky, M. G., Moreno, P., & Soto, V. (2018). Multi-dialectical languages effect on speech recognition: Too much choice can hurt. Procedia Computer Science, 128, 1-8.
Etman, A., & Beex, A. L. (2015, November). Language and dialect identification: A survey. In 2015 SAI intelligent systems conference (IntelliSys) (pp. 220-231). IEEE.
Gurbuz, S., Gowdy, J. N., & Tufekci, Z. (2000, April). Speech spectrogram-based model adaptation for speaker identification. In Proceedings of the IEEE SoutheastCon 2000.'Preparing for The New Millennium'(Cat. No. 00CH37105) (pp. 110-115). IEEE.
He, J., Ding, L., Jiang, L., & Ma, L. (2014, July). Kernel ridge regression classification. In 2014 International Joint Conference on Neural Networks (IJCNN) (pp. 2263-2267). IEEE.
Kale, S., & Prasad, R. (2018). Author identification on imbalanced class dataset of Indian literature in Marathi. International Journal of Computer Sciences and Engineering, 6, 542-547.
Khalid, S., Khalil, T., & Nasreen, S. (2014, August). A survey of feature selection and feature extraction techniques in machine learning. In 2014 science and information conference (pp. 372-378). IEEE.
Mamyrbayev, O., Mekebayev, N., Turdalyuly, M., Oshanova, N., Medeni, T. I., & Yessentay, A. (2019). Voice identification using classification algorithms. Intelligent System and Computing.
Masood, S., Nayal, J. S., Jain, R. K., Doja, M. N., & Ahmad, M. (2017). MFCC, Spectral and Temporal Feature based Emotion Identification in Songs. International Journal of Hybrid Information Technology, 10(5), 29-40.
Mohammed, T. S., Aljebory, K. M., Rasheed, M. A. A., Al-Ani, M. S., & Sagheer, A. M. (2021). Analysis of Methods and Techniques Used for Speaker Identification, Recognition, and Verification: A Study on Quarter-Century Research Outcomes. Iraqi Journal of Science, 3256-3281.
Moh'd A Mesleh, A. (2007). Chi square feature extraction based svms Arabic language text categorization system. Journal of Computer Science, 3(6), 430-435.
Muslim, E. M. (2007). An Introduction to Computational Linguistics Advantages & Disadvantages. journal of the college of basic education, 10(51).
Nisar, S., & Tariq, M. (2018). Dialect recognition for low resource language using an adaptive filter bank. International Journal of Wavelets, Multiresolution and Information Processing, 16(04), 1850031.
Prasad, J. R., & Kulkarni, U. (2015). Gujrati character recognition using weighted k-NN and mean ? 2 distance measure. International Journal of Machine Learning and Cybernetics, 6(1), 69-82.
Ramamoorthy, L., Narayan Choudhary, Gajanan R Apine & Apurva P Betkekar. 2019. Marathi Raw Speech Corpus. Central Institute of Indian Languages, Mysore.
Rao, K. S., Nandy, S., & Koolagudi, S. G. (2010). Identification of Hindi dialects using speech. WMSCI-2010.
Ren, Z., Yang, G., & Xu, S. (2019). Two-stage training for Chinese dialect recognition. arXiv preprint arXiv:1908.02284.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge university press.
Sheng, L. M. A., & Edmund, M. W. X. (2017). Deep learning approach to accent classification. CS229.
Shivaprasad, S., & Sadanandam, M. (2021). Dialect recognition from Telugu speech utterances using spectral and prosodic features. International Journal of Speech Technology, 1-10.
Singh, G., Sharma, S., Kumar, V., Kaur, M., Baz, M., & Masud, M. (2021). Spoken Language Identification Using Deep Learning. Computational Intelligence and Neuroscience, 2021.
Smola, A., & Vishwanathan, S. V. N. (2008). Introduction to machine learning. Cambridge University, UK, 32(34), 2008.
Sreeraj, V. V., & Rajan, R. (2017, May). Automatic dialect recognition using feature fusion. In 2017 International Conference on Trends in Electronics and Informatics (ICEI) (pp. 435-439). IEEE.
Subasi, A. (2019). Feature Extraction and Dimension Reduction, Practical Guide for Biomedical Signals Analysis Using Machine Learning Techniques, Academic Press.193-275
Thomas, S., Ganapathy, S., & Hermansky, H. (2008, August). Spectro-temporal features for automatic speech recognition using linear prediction in spectral domain. In 2008 16th European Signal Processing Conference (pp. 1-4). IEEE.
McFee, B., Raffel, C., Liang, D., Ellis, D. P., McVicar, M., Battenberg, E., & Nieto, O. (2015). librosa: Audio and music signal analysis in python. In Proceedings of the 14th python in science conference (Vol. 8).