A Novel Approach for Speech to Text Recognition System Using Hidden Markov Model
Article Sidebar
Main Article Content
Abstract
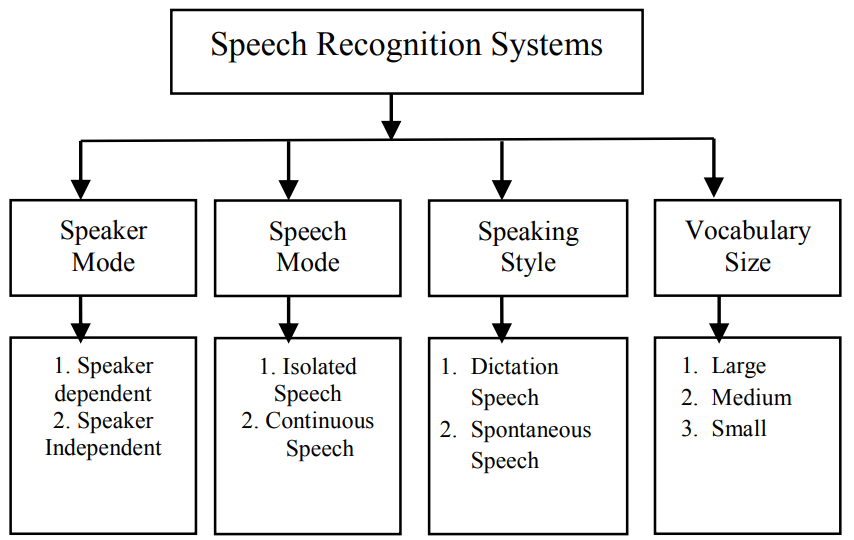
Speech recognition is the application of sophisticated algorithms which involve the transforming of the human voice to text. Speech identification is essential as it utilizes by several biometric identification systems and voice-controlled automation systems. Variations in recording equipment, speakers, situations, and environments make speech recognition a tough undertaking. Three major phases comprise speech recognition: speech pre-processing, feature extraction, and speech categorization. This work presents a comprehensive study with the objectives of comprehending, analyzing, and enhancing these models and approaches, such as Hidden Markov Models and Artificial Neural Networks, employed in the voice recognition system for feature extraction and classification.
Article Details
References
Amberkar, A., Awasarmol, P., Deshmukh, G., & Dave, P. (2018, March). Speech recognition using recurrent neural networks. In 2018 international conference on current trends towards converging technologies (ICCTCT) (pp. 1-4). IEEE.
Singh, A. P., Nath, R., & Kumar, S. (2018, November). A survey: Speech recognition approaches and techniques. In 2018 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON) (pp. 1-4). IEEE.
Chavan, R. S., & Sable, G. S. (2013). An overview of speech recognition using HMM. International Journal of Computer Science and Mobile Computing, 2(6), 233-238.
Desai, N., Dhameliya, K., & Desai, V. (2013). Feature extraction and classification techniques for speech recognition: A review. International Journal of Emerging Technology and Advanced Engineering, 3(12), 367-371.
Bapna, A., Cherry, C., Zhang, Y., Jia, Y., Johnson, M., Cheng, Y., ... & Conneau, A. (2022). mSLAM: Massively multilingual joint pre-training for speech and text. arXiv preprint arXiv:2202.01374.
Chen, Z., Zhang, Y., Rosenberg, A., Ramabhadran, B., Moreno, P., Bapna, A., & Zen, H. (2022). MAESTRO: Matched Speech Text Representations through Modality Matching. arXiv preprint arXiv:2204.03409.
Patel, I., & Rao, Y. S. (2010, March). Speech recognition using hidden Markov model with MFCC-subband technique. In 2010 International Conference on Recent Trends in Information, Telecommunication and Computing (pp. 168-172). IEEE.
Chung, Y. A., Zhang, Y., Han, W., Chiu, C. C., Qin, J., Pang, R., & Wu, Y. (2021, December). W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 244-250). IEEE.
Parthasarathi, S. H. K., & Strom, N. (2019, May). Lessons from building acoustic models with a million hours of speech. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6670-6674). IEEE.
Guo, C. Y., Hsieh, T. L., Chang, C. C., & Perng, J. W. A Novel Smart Photoelectric Lock System: Speech Transmitted by Laser and Speech to Text. Available at SSRN 4268119.
Akther, A., & Debnath, R. (2022). AUTOMATED SPEECH-TO-TEXT CONVERSION SYSTEMS IN BANGLA LANGUAGE: A SYSTEMATIC LITERATURE REVIEW. Khulna University Studies, 566-583.
Wahyutama, A. B., & Hwang, M. (2022, July). Performance Comparison of Open Speech-To-Text Engines using Sentence Transformer Similarity Check with the Korean Language by Foreigners. In 2022 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT) (pp. 97-101). IEEE.
Venkatasubramanian, S., & Mohankumar, R. (2022). A Deep Convolutional Neural Network-Based Speech-to-Text Conversion for Multilingual Languages. In Computational Vision and Bio-Inspired Computing (pp. 617-633). Springer, Singapore.
Trivedi, A., Pant, N., Shah, P., Sonik, S., & Agrawal, S. (2018). Speech to text and text to speech recognition systems-Areview. IOSR J. Comput. Eng, 20(2), 36-43.
Ohta, M., Kreutzer, J., & Riezler, S. (2022). JoeyS2T: Minimalistic Speech-to-Text Modeling with JoeyNMT. arXiv preprint arXiv:2210.02545