Spatio-Temporal Human Action Recognition Model using Deep Learning Techniques
Article Sidebar
Main Article Content
Abstract
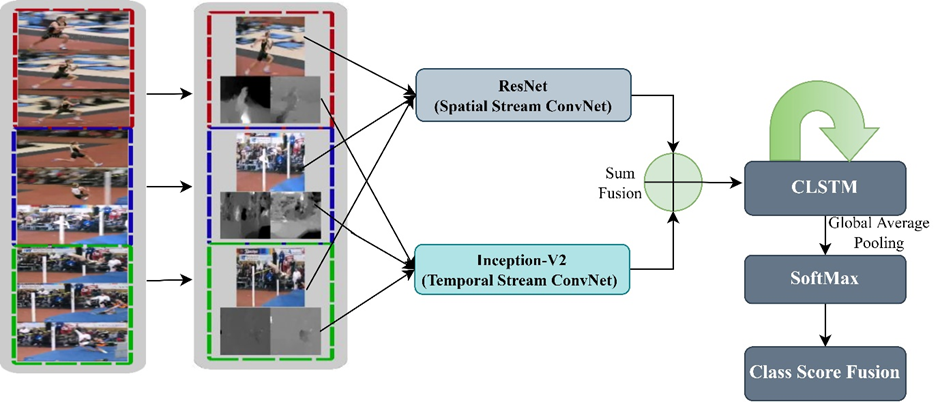
Two-stream human recognition achieved great success in the development of video action recognition using deep learning. Recently many studies have shown that two-stream action recognition is a powerful feature extractor. The main contribution in this work is to develop a two-stream model based on spatial and temporal networks using convolutional neural networks with a convolution long-short term memory. The two-stream model with ImageNet pre-trained weights is used to retrieve spatial and temporal features. Output feature maps of the two-stream model are fused using sum fusion and fed as input to convolutional long-short-term memory. SoftMax function is used to get the final classification score. To avoid overfitting, we have adopted the data augmentation techniques. Finally, we demonstrated that the proposed model performs well in comparison to state-of-the-art two-stream models with an accuracy of 96.1% on UCF 101 dataset and 70.9% accuracy on the HMDB dataset.
Article Details
References
A. Gaidon, Z. Harchaoui, and C. Schmid, “Temporal localization of actions with actoms,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 11, pp. 2782–2795, 2013.
J. C. Niebles, C.-W. Chen, and L. Fei-Fei, “Modeling temporal structure of decomposable motion segments for activity classification,” in European conference on computer vision, 2010, pp. 392–405.
L. Wang, Y. Qiao, and X. Tang, “Latent hierarchical model of temporal structure for complex activity classification,” IEEE Transactions on Image Processing, vol. 23, no. 2, pp. 810–822, 2013.
K. Simonyan and A. Zisserman, “Two-Stream Convolutional Networks for Action Recognition in Videos,” in Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1, Cambridge, MA, USA, 2014, pp. 568–576.
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4489–4497.
J. Donahue et al., “Long-Term Recurrent Convolutional Networks for Visual Recognition and Description,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 677–691, Apr. 2017, doi: 10.1109/TPAMI.2016.2599174.
G. Varol, I. Laptev, and C. Schmid, “Long-term temporal convolutions for action recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1510–1517, 2017.
L. Wang et al., “Temporal segment networks: Towards good practices for deep action recognition,” in European conference on computer vision, 2016, pp. 20–36.
A. Sarabu and A. K. Santra, “Distinct two-stream convolutional networks for human action recognition in videos using segment-based temporal modeling,” Data, vol. 5, no. 4, p. 104, 2020.
C.-Y. Ma, M.-H. Chen, Z. Kira, and G. AlRegib, “TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition,” Signal Processing: Image Communication, vol. 71, pp. 76–87, 2019.
G. Zhu, L. Zhang, P. Shen, and J. Song, “Multimodal gesture recognition using 3-D convolution and convolutional LSTM,” Ieee Access, vol. 5, pp. 4517–4524, 2017.
X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W. Woo, “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” Advances in neural information processing systems, vol. 28, 2015.
G. Cheng, Y. Wan, A. N. Saudagar, K. Namuduri, and B. P. Buckles, “Advances in human action recognition: A survey,” arXiv preprint arXiv:1501.05964, 2015.
S. Herath, M. Harandi, and F. Porikli, “Going deeper into action recognition: A survey,” Image and vision computing, vol. 60, pp. 4–21, 2017.
H.-B. Zhang et al., “A comprehensive survey of vision-based human action recognition methods,” Sensors, vol. 19, no. 5, p. 1005, 2019.
L. Wang, Y. Qiao, and X. Tang, “Action recognition with trajectory-pooled deep-convolutional descriptors,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4305–4314.
C. Feichtenhofer, A. Pinz, and A. Zisserman, “Convolutional two-stream network fusion for video action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1933–1941.
R. Christoph and F. A. Pinz, “Spatiotemporal residual networks for video action recognition,” Advances in neural information processing systems, pp. 3468–3476, 2016.
Y. Wang, M. Long, J. Wang, and P. S. Yu, “Spatiotemporal pyramid network for video action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1529–1538.
J. Ji, S. Buch, A. Soto, and J. C. Niebles, “End-to-end joint semantic segmentation of actors and actions in video,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 702–717.
B. Sengupta and Y. Qian, “Pillar Networks for action recognition,” in IROS Workshop on Semantic Policy and Action Representations for Autonomous Robots, 2017.
W. Zhu, J. Hu, G. Sun, X. Cao, and Y. Qiao, “A key volume mining deep framework for action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1991–1999.
B. Sengupta and Y. Qian, “Pillar networks++: Distributed non-parametric deep and wide networks,” arXiv preprint arXiv:1708.06250, 2017.
S. Sharma, R. Kiros, and R. Salakhutdinov, “Action recognition using visual attention,” arXiv preprint arXiv:1511.04119, 2015.
M. A. Goodale and A. D. Milner, “Separate visual pathways for perception and action,” Trends in neurosciences, vol. 15, no. 1, pp. 20–25, 1992.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
W. Yu, K. Yang, Y. Bai, T. Xiao, H. Yao, and Y. Rui, “Visualizing and comparing AlexNet and VGG using deconvolutional layers,” in Proceedings of the 33 rd International Conference on Machine Learning, 2016.
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
C. Szegedy et al., “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in International conference on machine learning, 2015, pp. 448–456.
C. Zach, T. Pock, and H. Bischof, “A duality based approach for realtime tv-l 1 optical flow,” in Joint pattern recognition symposium, 2007, pp. 214–223.
T. Brox, A. Bruhn, N. Papenberg, and J. Weickert, “High accuracy optical flow estimation based on a theory for warping,” in European conference on computer vision, 2004, pp. 25–36.
J. Yue-Hei Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici, “Beyond short snippets: Deep networks for video classification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4694–4702.
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308.
A. Sarabu and A. K. Santra, “Human action recognition in videos using convolution long short-term memory network with spatio-temporal networks,” Emerging Science Journal, vol. 5, no. 1, pp. 25–33, 2021.
X. Wu and Q. Ji, “TBRNet: Two-stream BiLSTM residual network for video action recognition,” Algorithms, vol. 13, no. 7, p. 169, 2020.