Fine Tuning Transformer Based BERT Model for Generating the Automatic Book Summary
Article Sidebar
Main Article Content
Abstract
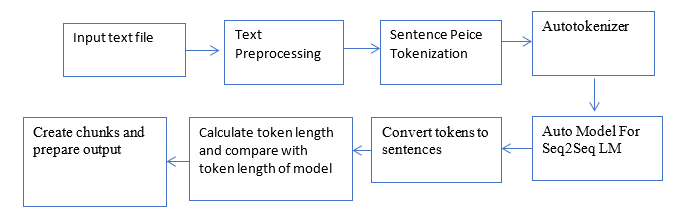
Major text summarization research is mainly focusing on summarizing short documents and very few works is witnessed for long document summarization. Additionally, extractive summarization is more addressed as compared with abstractive summarization. Abstractive summarization, unlike extractive summarization, does not only copy essential words from the original text but requires paraphrasing to get close to human generated summary. The machine learning, deep learning models are adapted to contemporary pre-trained models like transformers. Transformer based Language models gaining a lot of attention because of self-supervised training while fine-tuning for Natural Language Processing (NLP) downstream task like text summarization. The proposed work is an attempt to investigate the use of transformers for abstraction. The proposed work is tested for book especially as a long document for evaluating the performance of the model.
Article Details
References
N. S. Shirwandkar and S. Kulkarni, “Extractive Text Summarization Using Deep Learning,” Proc. - 2018 4th Int. Conf. Comput. Commun. Control Autom. ICCUBEA 2018, 2018, doi: 10.1109/ICCUBEA.2018.8697465.
S. Singhal, “Abstractive Text Summarization,” J. Xidian Univ., vol. 14, no. 6, pp. 1–11, 2020, doi: 10.37896/jxu14.6/094
D. Suleiman and A. Awajan, “Deep Learning Based Abstractive Text Summarization: Approaches, Datasets, Evaluation Measures, and Challenges,” Math. Probl. Eng., vol. 2020, 2020, doi: 10.1155/2020/9365340.
A. Vaswani et al., “Attention is all you need,” Adv. Neural Inf. Process. Syst., vol. 2017-December, no. Nips, pp. 5999–6009, 2017.
S. Singh and A. Mahmood, “The NLP Cookbook: Modern Recipes for Transformer Based Deep Learning Architectures,” IEEE Access, vol. 9, pp. 68675–68702, 2021, doi: 10.1109/ACCESS.2021.3077350.
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” NAACL HLT 2019 - 2019 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. - Proc. Conf., vol. 1, no. Mlm, pp. 4171–4186, 2019.
N. Andhale and L. A. Bewoor, “An overview of text summarization techniques,” 2017, doi: 10.1109/ICCUBEA.2016.7860024.
D. Hingu, D. Shah, and S. S. Udmale, “Automatic text summarization of Wikipedia articles,” Proc. - 2015 Int. Conf. Commun. Inf. Comput. Technol. ICCICT 2015, pp. 15–18, 2015, doi: 10.1109/ICCICT.2015.7045732.
Y. Liu and M. Lapata, “Text summarization with pretrained encoders,” EMNLP-IJCNLP 2019 - 2019 Conf. Empir. Methods Nat. Lang. Process. 9th Int. Jt. Conf. Nat. Lang. Process. Proc. Conf., pp. 3730–3740, 2019, doi: 10.18653/v1/d19-1387.
T. Ma, Q. Pan, H. Rong, Y. Qian, Y. Tian and N. Al-Nabhan, "T-BERTSum: Topic-Aware Text Summarization Based on BERT," in IEEE Transactions on Computational Social Systems, vol. 9, no. 3, pp. 879-890, June 2022, doi: 10.1109/TCSS.2021.3088506.
K. N. Elmadani, M. Elgezouli, and A. Showk, “BERT Fine-tuning For Arabic Text Summarization,” pp. 2018–2021, 2020, [Online]. Available: http://arxiv.org/abs/2004.14135
H. Zhang, J. Cai, J. Xu, and J. Wang, “Pretraining-based natural language generation for text summarization,” CoNLL 2019 - 23rd Conf. Comput. Nat. Lang. Learn. Proc. Conf., pp. 789–797, 2019, doi: 10.18653/v1/k19-1074.
Y. Iwasaki, A. Yamashita, Y. Konno and K. Matsubayashi, "Japanese abstractive text summarization using BERT," 2019 International Conference on Technologies and Applications of Arti?cial Intelligence (TAAI), 2019, pp. 1-5, doi: 10.1109/TAAI48200.2019.8959920.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for LanguageUnderstanding.” https://arxiv.org/pdf/1810.04805.pdf