On Optimality of Long Document Classification using Deep Learning
Article Sidebar
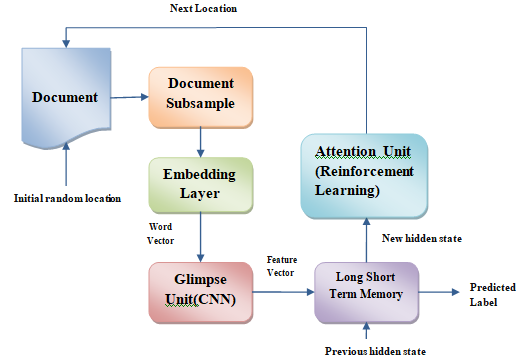
Main Article Content
Abstract
Document classification is effective with elegant models of word numerical distributions. The word embeddings are one of the categories of numerical distributions of words from the WordNet. The modern machine learning algorithms yearn on classifying documents based on the categorical data. The context of interest on the categorical data is posed with weights and the sense and quality of the sentences is estimated for sensible classification of documents. The focus of the current work is on legal and criminal documents extracted from the popular news channels, particularly on classification of long length legal and criminal documents. Optimization is the essential instrument to bring the quality inputs to the document classification model. The existing models are studied and a feasible model for the efficient document classification is proposed. The experiments are carried out with meticulous filtering and extraction of legal and criminal records from the popular news web sites and preprocessed with WordNet and Text Processing contingencies for efficient inward for the learning framework.
Article Details
References
Choi, Gihyeon, Shinhyeok Oh, and Harksoo Kim. “Improving document-level sentiment classification using importance of sentences.” Entropy 22, no. 12 (2020): 1336.
Park, Hyunji Hayley, Yogarshi Vyas, and Kashif Shah. “Efficient Classification of Long Documents Using Transformers.” arXiv preprint arXiv:2203.11258 (2022).
Khoo, Anthony, Yuval Marom, and David Albrecht. “Experiments with sentence classification.” In Proceedings of the Australasian Language Technology Workshop 2006, pp. 18-25. 2006.
Nikolaidou, Konstantina, Mathias Seuret, Hamam Mokayed, and Marcus Liwicki. “A Survey of Historical Document Image Datasets.” arXiv preprint arXiv:2203.08504 (2022)
Kišš, Martin, Jan Kohút, Karel Beneš, and Michal Hradiš. “Importance of Textlines in Historical Document Classification.” In International Workshop on Document Analysis Systems, pp. 158-170. Springer, Cham, 2022.
Jiang, Shuo, Jie Hu, Christopher L. Magee, and Jianxi Luo. “Deep learning for technical document classification.” IEEE Transactions on Engineering Management (2022).
Noguti, Mariana Y., Eduardo Vellasques, and Luiz S. Oliveira. “Legal document classification: An application to law area prediction of petitions to public prosecution service.” In 2020 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. IEEE, 2020.
Wan, Lulu, George Papageorgiou, Michael Seddon, and Mirko Bernardoni. “Long-length legal document classification.” arXiv preprint arXiv:1912.06905 (2019).
Hassanzadeh, Hamed, Mahnoosh Kholghi, Anthony Nguyen, and Kevin Chu. “Clinical document classification using labeled and unlabeled data across hospitals.” In AMIA annual symposium proceedings, vol. 2018, p. 545. American Medical Informatics Association, 2018.
Stein, Roger Alan, Patricia A. Jaques, and Joao Francisco Valiati. “An analysis of hierarchical text classification using word embeddings.” Information Sciences 471 (2019): 216-232.
Wagh, Vedangi, Snehal Khandve, Isha Joshi, Apurva Wani, Geetanjali Kale, and Raviraj Joshi. “Comparative study of long document classification.” In TENCON 2021-2021 IEEE Region 10 Conference (TENCON), pp. 732-737. IEEE, 2021