DBRS: Directed Acyclic Graph based Reliable Scheduling Approach in Large Scale Computing
Article Sidebar
Main Article Content
Abstract
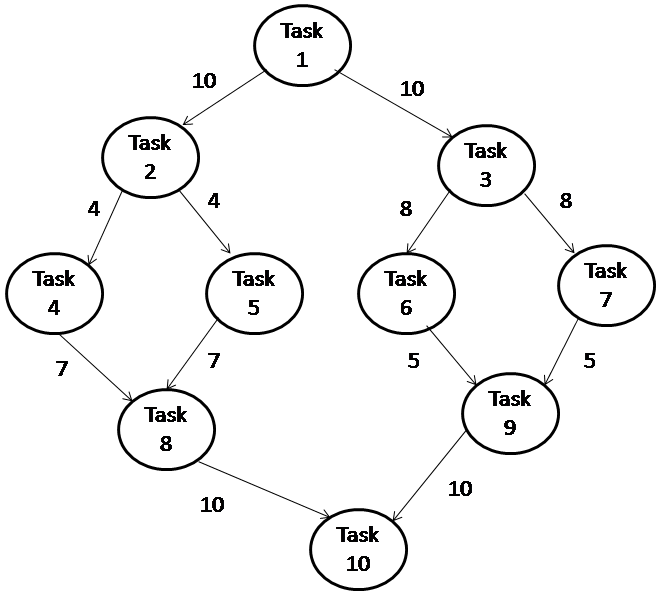
In large scale environments, scheduling presents a significant challenge because it is an NP-hard problem. There are basically two types of task in execution- dependent task and independent task. The execution of dependent task must follow a strict order because output of one activity is typically the input of another. In this paper, a reliable fault tolerant approach is proposed for scheduling of dependent task in large scale computing environments. The workflow of dependent task is represented with the help of a DAG (directed acyclic graph). The proposed methodology is evaluated over various parameters by applying it in a large scale computing environment- ‘grid computing’. Grid computing is a high performance computing for solving complex, large and data intensive problems in various fields. The result analysis shows that the proposed DAG based reliable scheduling (DBRS) approach increases the performance of system by decreasing the makespan, number of failures and increasing performance improvement ratio (PIR).
Article Details
References
Manjot Kaur Bhatia, "Task Scheduling in Grid Computing: A Review", Advances in Computational Sciences and Technology ISSN 0973-6107 10(6) (2017) 1707-1714.
H. B. Prajapati, V. A. Shah, "Scheduling in Grid Computing Environment". 2014 Fourth International Conference on Advanced Computing & Communication Technologies, ISBN:978-1-4799-4910-6, DOI: 10.1109/ACCT.2014.32, (2014).
S. Haider and B. Nazir, “Fault tolerance in computational grids: perspectives, challenges, and issues”, Springer Plus, Vol. 5, pp. 1-20, 2016
R. Garg and A. K. Singh, “Fault Tolerance in Grid Computing: State of the Art and Open Issues”, International Journal of Computer Science & Engineering Survey (IJCSES), Vol. 2, No. 1, pp. 88-97, 2011.
R. Garg and A. K. Singh, “Fault Tolerant Task Scheduling on Computational Grid Using Checkpointing Under Transient Faults”, Springer, Arab J Sci Eng, Vol. 39, pp. 8775–8791, 2014.
R. Garg and A. K. Singh. “Adaptive workflow scheduling in grid computing based on dynamic resource availability”, Engineering Science and Technology, an International Journal, Vol. 18, pp. 256-269, 2015.
Yang Zhang, Anirban Mandal, Charles Koelbel and Keith Cooper, "Combined Fault Tolerance and Scheduling Techniques for Workflow Applications on Computational Grids", 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, pp 244-251, 2009, ISBN: 978-0-7695-3622-4/09, DOI 10.1109/CCGRID.2009.59
A. Iosup, M. Jan, O. Sonmez and D. H. J. Epema,"On the Dynamic Resource Availabilty in Grids" IEEE 8th Grid Computing Conference, pp. 26-33, 2007.
Zhifeng Yu, Chenjia Wang and Weisong Shi, "Failure-aware workflow scheduling in cluster environments",Cluster Comput, Vol. 13, pp. 421–434, 2010. DOI 10.1007/s10586-010-0126-7.
Liang Yu, Gang Zhou, Yifei Pu, “An Improved Task Scheduling Algorithm in Grid Computing Environment”, Int. J. Communications, Network and System Sciences, Vol. 4, pp. 227-231, 2011. DOI:10.4236/ijcns.2011.44027.
Cheng-Chi Lee, Hsien-Ju Ko & Shun-Der Chen, An improved simple user authentication scheme for grid computing, Journal of Discrete Mathematical Sciences and Cryptography, Vol. 15(2-3), pp. 113-124, 2012. DOI: 10.1080/09720529.2012.10698368
Ren Changan, Jinguo Zhao & Liping Chen, A fast information scheduling algorithm for large scale logistics supply chain, Journal of Discrete Mathematical Sciences and Cryptography, Vol. 20(6-7), pp. 1459-1463, 2017. DOI:10.1080/09720529.2017.1392463
Harvinder Singh, Anshu Bhasin & Parag Kaveri, SECURE : Efficient resource scheduling by swarm in cloud computing, Journal of Discrete Mathematical Sciences and Cryptography, Vol. 22(2), pp. 127-137, 2019. DOI: 10.1080/09720529.2019.1576334.
Mahendra Kumar Gourisaria, Pabitra Mohan Khilar & Sudhansu Shekhar Patra, EPTS: Energy-saving pre-emptive task scheduling for homogeneous cloud systems, Journal of Discrete Mathematical Sciences and Cryptography, Vol. 24(8), pp. 2415-2441, 2021. DOI: 10.1080/09720529.2021.2016191.
P. Jiang, Y. Xing, X. Jia, and B. Guo, “Weibull Failure Probability Estimation Based on Zero-Failure Data”, Hindawi Publishing Corporation, Mathematical Problems in Engineering Volume , pp. 1-8, 2015.
Lulu Zhang , Guang Jin, and Yang You, “Reliability Assessment for Very Few Failure Data and Weibull Distribution”, Mathematical Problems in Engineering, Hindawi, Vol. 2019, pp. 1-9, 2019. https://doi.org/10.1155/2019/8947905.
Cappello, F.: Modeling and tolerating heterogeneous failures in large parallel systems. In: Proceedings of the SC’2011 International Conference for High Performance Computing, Networking, Storage and Analysis, ACM Press (2011)
Liu, Y.; Nassar, N.; Leangsuksun, C.; Nichamon, N.; Paun, M.; Scott, S.: An optimal checkpoint/restart model for a large scale high performance computing system. In: IEEE International Symposium on Parallel and Distributed Processing (IPDPS 2008), pp. 1–9 (2009)
Schroeder, B.;Gibson, G.A.:Alarge-scale study of failures in highperformance computing system. IEEE Trans. Dependable Secur. Comput. 7(4), 337–350 (2010).
Manjeet Singh and Javalkar Dinesh Kumar (2022), Designing and Implementation of Failure-Aware Based Approach for Task Scheduling in Grid Computing. IJEER 10(3), 651-658. DOI: 10.37391/IJEER.100339.