Identifying Arrhythmias Based on ECG Classification Using Enhanced-PCA and Enhanced-SVM Methods
Article Sidebar
Main Article Content
Abstract
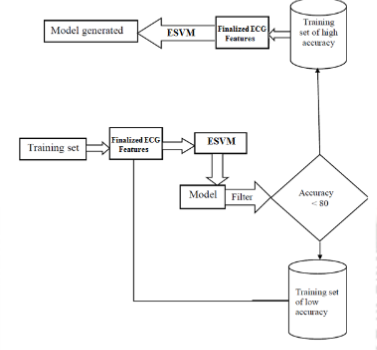
The "Cardio Vascular Diseases (CVDs)" had already attained worrisome proportions in both advanced and emerging nations in recent times. Physically inactive behaviors, altered eating, and occupational routines, and reduced daily fitness were all recognized as crucial contextual elements, in addition to genetics. Considering CVDs have such a significant morbidity and mortality, accurate and early diagnosis of cardiac disease by "ElectroCardioGram (ECG)" allows clinicians to decide suitable therapy for a multitude of cardiovascular disorders. The interpretation of ECG signal is an important bio-signal processing area that involves the application of computer science and engineering to detect and visualize the functional status of the heart. Therefore, in the present work, a detailed study on ECG signals denoising and abnormalities detection using different techniques were performed. Annoying distortions and noisy particles are common in ECG signals. The "Biased Finite Impulse Response (BFIR)" preprocessing filtering is employed in this research to eliminate the noises in the raw ECG signals. The "Nonlinear-Hamilton" segmentation method is employed to segment the 'R' peak signals. To decrease the extraneous features included in the segmented ECG data, the innovative "Enhanced Principal Component Analysis (EPCA)" was applied for feature extraction. A unique "Enhanced version of the Support Vector Machine (ESVM)" framework with a "Weighting Kernel" based technique is proposed for classifying the ECG data. The 'Q', 'R', and 'S' waves in the given ECG data will be identified by this framework, allowing it to characterize the cardiac rhythm. The evaluation metrics of the EPCA-ESVM proposed method is comparatively analyzed with our previous approach EPSO. To estimate the results for the dataset from MIT-BIH it was experimented with by the EPSO and the EPCA-ESVM methods focused upon different parameters such as Accuracy, F1-score, etc. The final findings of the EPCA-ESVM method were good than the EPSO method in which the accuracy is higher even though unbalanced data were present.