Leveraging a Hybrid Deep Learning Architecture for Efficient Emotion Recognition in Audio Processing
Article Sidebar
Main Article Content
Abstract
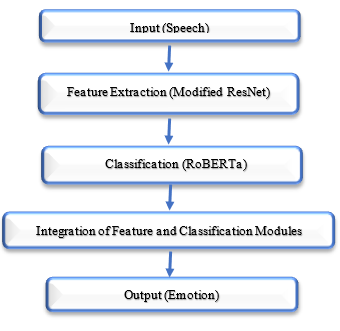
This paper presents a novel hybrid deep learning architecture for emotion recognition from speech signals, which has garnered significant interest in recent years due to its potential applications in various fields such as healthcare, psychology, and entertainment. The proposed architecture combines modified ResNet-34 and RoBERTa models to extract meaningful features from speech signals and classify them into different emotion categories. The model is evaluated on five standard emotion recognition datasets, including RAVDESS, EmoDB, SAVEE, CREMA-D, and TESS, and achieves state-of-the-art performance on all datasets. The experimental results show that the proposed hybrid architecture outperforms existing emotion recognition models, achieving high accuracy and F1 scores for emotion classification. The proposed architecture is promising for real-time emotion recognition applications and can be applied in various domains such as speech-based emotion recognition systems, human-computer interaction, and virtual assistants.
Article Details
References
Schuller, B., Batliner, A., Steidl, S., & Seppi, D. (2011). Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech communication, 53(9-10), 1062-1087.
Satt, A., Rozenberg, S., & Hoory, R. (2017, August). Efficient emotion recognition from speech using deep learning on spectrograms. In Interspeech (pp. 1089-1093).
Zhao, J., Mao, X., & Chen, L. (2019). Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomedical signal processing and control, 47, 312-323.
Stuhlsatz, A., Meyer, C., Eyben, F., Zielke, T., Meier, G., & Schuller, B. (2011, May). Deep neural networks for acoustic emotion recognition: Raising the benchmarks. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5688-5691). IEEE.
Zhao, Z., Bao, Z., Zhao, Y., Zhang, Z., Cummins, N., Ren, Z., & Schuller, B. (2019). Exploring deep spectrum representations via attention-based recurrent and convolutional neural networks for speech emotion recognition. IEEE Access, 7, 97515-97525.
Gao, H., Mao, Y., Zhou, X., & Huang, X. (2019). A hybrid CNN-RNN architecture for speech emotion recognition. IEEE Access, 7, 99578-99586.
Li, Y., Shen, Y., Bai, X., Liu, B., & Zhang, X. (2020). A Hybrid CNN-Transformer Model for Speech Emotion Recognition. In Proceedings of the 28th ACM International Conference on Multimedia (pp. 2272-2275).
Chen, Q., & Huang, G. (2021). A novel dual attention-based BLSTM with hybrid features in speech emotion recognition. Engineering Applications of Artificial Intelligence, 102, 104277.
Duan, B., Tang, H., Wang, W., Zong, Z., Yang, G., & Yan, Y. (2021). Audio-visual event localization via recursive fusion by joint co-attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 4013-4022).
Liu, X., Xu, H., & Wang, M. (2022). Sparse spatial-temporal emotion graph convolutional network for video emotion recognition. Computational Intelligence and Neuroscience, 2022.
Li, Z., Zou, Y., Zhang, H., Huang, L., Liu, X., & Qin, H. (2022). Speech Emotion Recognition Based on CNN and Graph Neural Network. IEEE Access, 10, 53213-53221.
Ye, J. X., Wen, X. C., Wang, X. Z., Xu, Y., Luo, Y., Wu, C. L., ... & Liu, K. H. (2022). GM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition. Speech Communication, 145, 21-35.
Fan, W., Xu, X., Cai, B., & Xing, X. (2022). ISNet: Individual standardization network for speech emotion recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 1803-1814.
Xia, X., & Jiang, D. (2023). HiT-MST: Dynamic facial expression recognition with hierarchical transformers and multi-scale spatiotemporal aggregation. Information Sciences, 119301.